Training an Agent on Public Vendor Data — A BigFix Workspace+ Case Study
How to build a contextual technical-support and architecture agent that is meaningfully better than a general LLM at one product, using nothing but publicly available vendor documentation. A walk-through of a working BigFix Workspace+ POC, the design decisions behind it, and the pattern that generalises to any vendor.
On this page
Ask a general-purpose LLM how to deploy an emergency Microsoft patch to ten thousand endpoints through HCL BigFix Workspace+, and you will get a plausible answer. Read it carefully and you will also find quietly invented menu paths, mis-named Fixlet sites, and “best practices” that no BigFix administrator has ever followed. The model has clearly seen the product once or twice during pre-training, just not enough to be useful when the deployment window opens at 10pm on a Tuesday.
This is the gap that specialist agents are meant to close. Not by retraining a foundation model — that is expensive, slow, and almost never the right tool — but by grounding a capable general model in a curated body of authoritative product knowledge that you control. The interesting part is that the body of knowledge required to make a model genuinely competent in a specific product is, for most enterprise vendors, already public. Administration guides, release notes, knowledge centre articles, support bulletins, hardening guides, command references — all of it sits on the vendor’s documentation site, free to read and free to index.
This post walks through a working proof-of-concept I built around exactly that idea: the BigFix Workspace+ Expert Agent, a Retrieval-Augmented Generation (RAG) specialist trained on public BigFix documentation. It is small enough to run on a laptop and good enough at its domain to demonstrate where this pattern earns its keep. More importantly, the architecture is product-agnostic — swap the knowledge base, change the system prompt, and the same pattern produces a specialist for VMware Horizon, ServiceNow ITSM, Citrix DaaS, Microsoft Intune, or any other vendor whose docs you can legally crawl.
Why General LLMs Are Not Good Enough For Product Depth
A general-purpose LLM pushed into vendor-specific territory tends to fail in the same five ways every time. A RAG-based specialist agent attacks all five at once — the knowledge base sits outside the model, can be refreshed when the vendor publishes a new release, retrieves verbatim passages instead of synthesising from memory, returns the source documents alongside every answer, and refuses to leave its declared domain.

The Premise — Public Vendor Data Is The Training Set
Enterprise software vendors publish an enormous amount of high-quality technical content for one reason: their customers cannot deploy or operate the product without it. HCL, Microsoft, VMware, Citrix, Red Hat, ServiceNow — all of them maintain extensive documentation sites and most also publish support knowledge bases, community forums, and architecture reference papers.
Three categories matter most for a support and architecture agent:
The first is product documentation — administration guides, deployment guides, console references, API references. This is your “how does the product work” layer. It is structured, versioned, and authoritative.
The second is knowledge base and support articles — the “how do you fix this when it breaks” layer. These articles are written by support engineers for symptoms that real customers have actually hit. They are gold for a troubleshooting agent.
The third is architecture and best-practice content — reference architectures, sizing guides, hardening guides, integration playbooks. This is your “how should you actually deploy it” layer.
Once you have those three corpora indexed, you have something that no general LLM has natively: a tight, current, citable body of knowledge with the depth that real practitioners need.
The Case Study — BigFix Workspace+ Expert Agent
HCL BigFix Workspace+ is a unified endpoint management platform — agent-based endpoint discovery, patch management for Windows / macOS / Linux / 100+ third-party apps, software distribution, CIS and STIG compliance scanning, and workspace analytics. It is a serious enterprise product and a representative target: the kind of platform where a general LLM is only superficially useful and where a specialist agent has obvious value for L1/L2 support, internal enablement, and architecture sanity-checks.
The POC ingests a curated set of public BigFix Workspace+ documentation across six domains:
- Product overview and architecture
- Patch management
- Troubleshooting
- Security and compliance
- Software distribution
- Workspace analytics
Each domain is a markdown document. In the POC the documents are hand-curated extracts; in a production deployment you would point the same pipeline at the vendor’s Knowledge Center, scrape it on a schedule, and feed the output straight through.
The Tech Stack along with production Swap:
| Component | POC | Production swap |
|---|---|---|
| LLM | OpenAI GPT-4o-mini | Azure OpenAI (enterprise compliance) |
| Embeddings | text-embedding-3-small | Azure OpenAI embeddings |
| Vector store | ChromaDB (local) | Azure AI Search / Pinecone |
| Orchestration | LangChain | LangGraph (multi-agent) |
| Web server | Flask | Azure Bot Framework + MS Teams |
| Auth | None | Azure AD / Teams SSO |
Cost to run a demo session sits well under ten cents in API calls. The whole system fits in a single repository and runs on a laptop with a Python virtual environment.
Architecture
The pipeline is the standard RAG topology, split into an offline ingestion stage (runs when the knowledge base is built or refreshed) and a runtime query stage (runs for every user question). The vector store is the shared component that bridges the two.
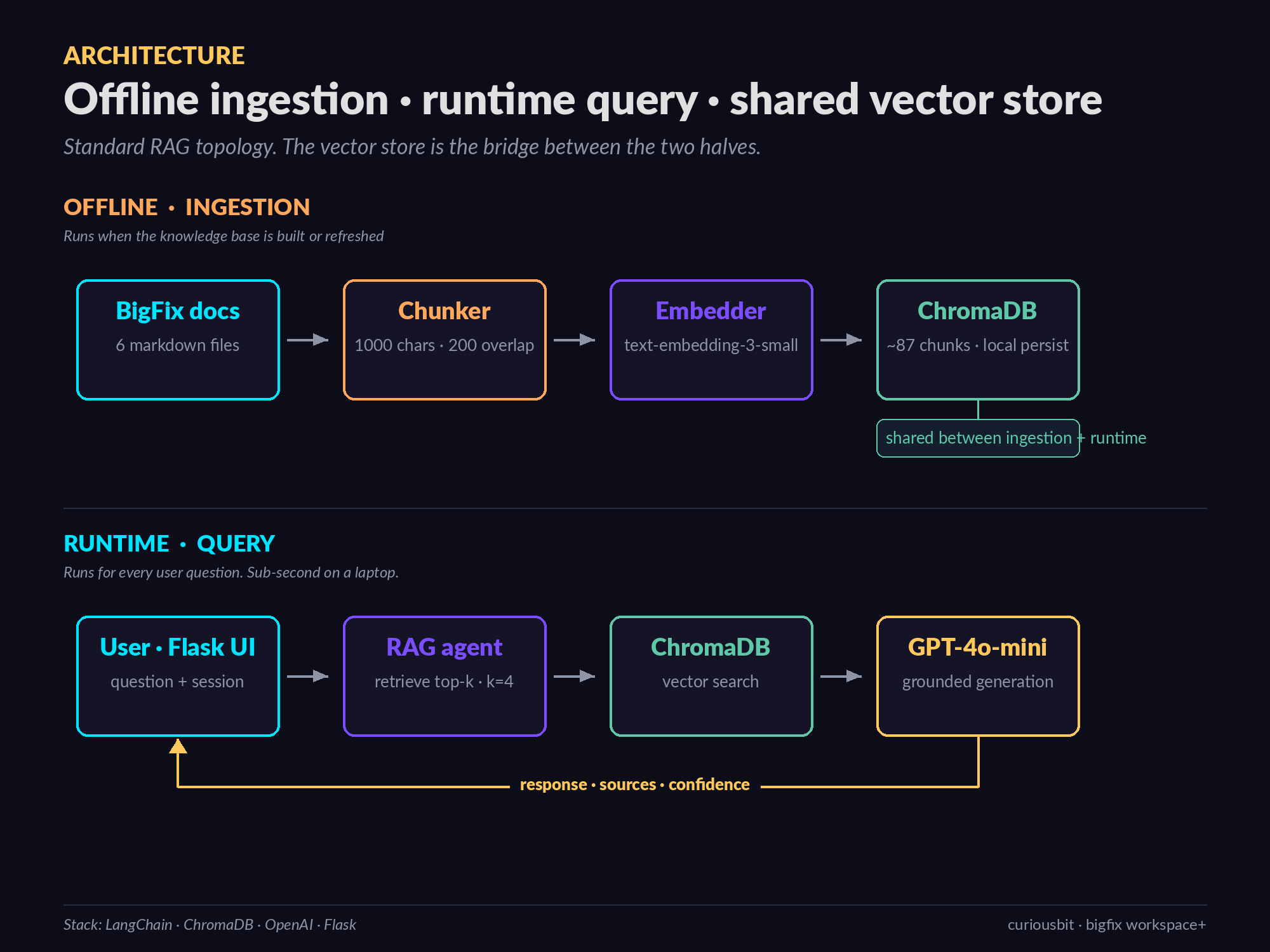
The Ingestion Pipeline

Three steps: load, chunk, embed.
Loading is mechanical — read every markdown file in the knowledge base directory, attach source metadata (filename plus a domain tag so multiple products can share a database later), and return a list of documents.
Chunking is where most of the retrieval quality is actually won or lost. The POC uses LangChain’s RecursiveCharacterTextSplitter with separators ordered from most to least semantic — heading-level breaks first, then paragraph breaks, then sentences, then words:
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\n## ", "\n### ", "\n#### ", "\n\n", "\n", ". ", " "],
)
The reason for this ordering matters. Technical documentation is dense with structured headings — “Creating a Patch Action”, “Patch Discovery”, “Maintenance Windows” — and a chunk that respects those boundaries reads as a coherent unit. A chunk that arbitrarily splits a numbered procedure in half does not. The 200-character overlap is there so that a sentence at the boundary still appears in both chunks; this materially improves recall when a user’s query phrasing matches text near a chunk edge.
Embeddings are produced with text-embedding-3-small — fast, cheap, and accurate enough for technical English. For a knowledge base of around six hundred lines of markdown the entire ingestion runs in under five seconds and produces roughly eighty to a hundred chunks.
The Agent
Two things make the agent specialised: the system prompt and the retrieval contract.
The system prompt establishes the agent’s persona, the rules of engagement, and — critically — the refusal policy. The relevant parts:
You are the BigFix Workspace+ Expert Agent, a specialist AI assistant for
HCL BigFix Workspace+ — a unified endpoint management platform.
Rules:
1. ONLY answer questions related to HCL BigFix Workspace+. If a question is
outside your domain, politely redirect.
2. Base your answers on the provided context. If the context doesn't contain
enough information, say so honestly rather than guessing.
3. When providing steps or commands, be specific and include the exact paths,
commands, or navigation instructions.
4. Always cite which area of BigFix your answer relates to.
The agent is told, explicitly, not to extrapolate. This is the lever that turns a chatty general-purpose model into something that behaves like a knowledgeable but appropriately humble support engineer. If the retrieved context does not address the question, the model is instructed to acknowledge the limitation rather than synthesise an answer from its parametric memory.
The retrieval contract is the second half of the specialisation. For every query, the agent retrieves the top-k chunks (k=4 in the POC) above a relevance threshold of 0.3, concatenates them into a single context block, and passes the question and context into the LLM. If retrieval returns nothing above threshold, the agent short-circuits and returns a polite “I do not have that in my knowledge base” response without ever calling the LLM. This is a small detail with a large effect — it prevents the model from confabulating answers when it has no evidence.
Confidence Scoring And Escalation
One of the design decisions I am most happy with is the explicit confidence score on every response. After generating an answer, the agent makes a second LLM call asking the model to rate how well the retrieved context actually addressed the question, on a scale of zero to one. If the score falls below a configurable threshold (default 0.7), the response carries an “escalation recommended” flag — surfaced in the UI as a coloured badge and, in production, used to route the question to a human L2 engineer or to a higher-tier orchestrator agent.
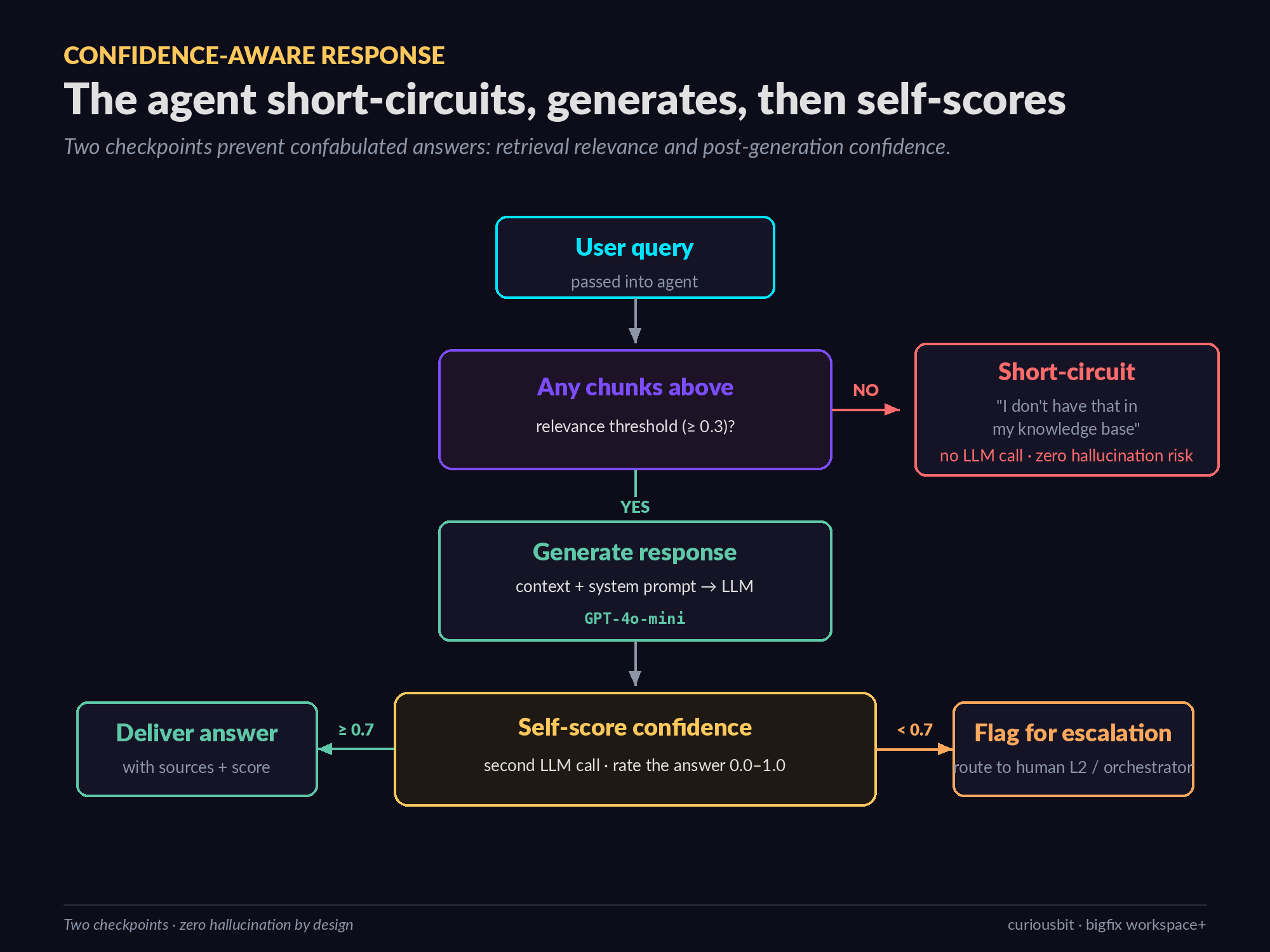
The result is a system that fails gracefully. It says “I don’t have that in my knowledge base” when retrieval comes back empty, and it raises a hand when retrieval succeeded but the response did not quite land. Very few naive RAG systems have either of those properties — most will confidently invent an answer either way.
Domain Guardrails
Ask the agent “what is the weather today” and it will not answer — not because it cannot, but because it has been instructed not to. The system prompt enforces a hard scope: BigFix Workspace+ questions only, everything else is politely redirected.
This sounds like a small thing. It is not. Domain isolation is the property that makes a specialist agent trustworthy in an enterprise setting. A general assistant that wanders out of its lane is a liability — it will eventually answer a question that the organisation needs answered by a different specialist team, or worse, by a human with accountability. A specialist agent that refuses to leave its lane is the agentic equivalent of a senior engineer who knows what they know and is honest about what they do not.
This pattern also composes. Run a BigFix agent, a ServiceNow agent, an Intune agent, and a VMware Horizon agent in the same workspace, and give an orchestrator agent the job of routing incoming questions to whichever specialist is best placed to answer. The result is something that starts to look like a real virtual support organisation.
What This Approach Actually Buys You Over A General LLM
Five things, concretely.
The first is currency. The knowledge base can be refreshed on whatever cadence the vendor publishes new content — daily for an actively maintained product, weekly for everything else. The model itself never has to be retrained. Re-running ingestion against an updated set of source documents is the entire change-management process.
The second is accuracy on product specifics. The answers come from passages that the vendor actually wrote, retrieved verbatim and handed to the LLM as context. The model still synthesises the response, but it is synthesising from authoritative source material rather than reaching into its compressed memory.
The third is auditability. Every response in the POC includes the list of source chunks that informed it, with relevance scores. A user — or an internal audit — can click into the sources and verify the claim against the underlying documentation.
The fourth is scope control. A general LLM will answer any question; a specialist agent answers only questions inside its declared domain. This is a feature, not a limitation. It is what makes the agent safe to deploy to a wide internal audience without needing to babysit its outputs.
The fifth is graceful failure. The combination of a relevance threshold on retrieval, an explicit “I don’t have that in my knowledge base” response when nothing scores above the threshold, and a confidence score on every answer means the agent fails by saying “I don’t know” rather than by inventing an answer.
From POC To Production
The POC deliberately stops short of production. Six things would have to change to take this into an enterprise environment, and none of them are difficult — they are all standard enterprise-platform substitutions.
The first is the LLM provider. Swap OpenAI for Azure OpenAI to get enterprise compliance, data residency, and an enterprise SLA. The LangChain code already supports both — flipping between them is an environment-variable change.
The second is the vector store. ChromaDB is excellent for local development; for production you want Azure AI Search or Pinecone, both of which give you horizontal scale, snapshotting, and managed availability. The retrieval interface is identical.
The third is authentication and access control. The Flask web UI is replaced with an Azure Bot Framework bot connected to MS Teams. The bot inherits Azure AD identity, which means every query is now tied to a named user, and access can be scoped per agent.
The fourth is observability. Add LangSmith or a custom logging layer to capture query, retrieved chunks, confidence, response, and user identity for every interaction. This becomes the dataset that drives knowledge-base improvement — every time the agent says “I don’t know”, that is a gap to fill.
The fifth is automated knowledge-base updates. Replace the manual python ingest.py invocation with a scheduled pipeline that crawls the vendor’s documentation site, diffs against the last snapshot, and reindexes only what changed.
The sixth is the multi-agent layer. Once you have a second specialist agent (say, ServiceNow ITSM), you introduce an orchestrator agent — built on LangGraph — whose job is to read the incoming question, decide which specialist is best placed to answer, and route accordingly. This is where the architecture starts to earn its name as an “agentic library”.
Generalising The Pattern
The thing I want to draw out here is that almost nothing in the architecture above is specific to BigFix. The system prompt names the product, the knowledge base contains BigFix documentation, and the UI says “BigFix Workspace+ Agent” at the top. Everything else — the ingestion pipeline, the retrieval logic, the confidence scoring, the escalation flag, the domain guardrails — is the same for any vendor whose documentation you can index.

That is it. The same six steps produce a Citrix DaaS architecture agent, a ServiceNow ITSM workflow assistant, a VMware Horizon troubleshooting bot, a Microsoft Intune compliance helper, a Red Hat OpenShift operator’s companion. Pick the product, find the docs, run the pipeline.
Closing Thought
The interesting shift here is not technical. The technical pattern — retrieval-augmented generation — has been in production at large enterprises for two years. What is interesting is that the data you need to make a specialist agent meaningfully better than a general LLM at a specific vendor product is already free and public. The vendor put it there because their customers need it to operate the product. We have spent twenty years building search engines, knowledge bases, and support portals on top of that documentation. A specialist agent is the natural next layer — one that reads those same documents, understands the question being asked, and answers in the form the user actually wanted.
For me, the BigFix POC is one node in a larger experiment around what an agentic IT support and architecture function could look like. A specialist agent per product, an orchestrator on top, a confidence-aware escalation path into human L2 / L3 — all of it grounded in the documentation that already exists. None of the individual pieces are exotic. The interesting thing is what happens when you assemble them.
If you operate a workplace or infrastructure team and you have a product domain where the same questions get asked over and over by the same engineers, this is a weekend’s worth of work. The vendor has already written your training set.

About the Author
Ajay Walia
AI {IT Architect} focusing on local-first multi-agent AI engineering, zero-data-egress systems. Ideator, Creator and Executor on Curious Bit.
Keep Reading

Essential Skills for the AI Era — What former British PM Says You Actually Need
AI is reshaping every job. The World Economic Forum, McKinsey, and peer-reviewed research agree on 17 skills that will define who thrives. Here they are — with how to build each one.
About
Learner 🎓 · Negotiator 🤝 · Architect 🏗️ · Implementer 👷 · Surviving — enabled by AI. Currently exploring: AI, Hybrid Cloud, Automation, Networks, Digital Workplace<br><br><em>"He who thinks he knows, knows not.<br>He who knows that he does not know, knows."</em>