Memory Management in LLMs
A structured hub on how large language models use, store, and optimize memory — from the bytes that hold model weights on a GPU to how an agent remembers across sessions. Pick a topic to dive in.
Everything about how large language models use, store, and optimize memory — from the bytes that hold model weights on a GPU to how an agent remembers a conversation across sessions. Each topic is tagged by when the memory is consumed. Pick a card to open the article.
System & Runtime Memory
How the model physically uses hardwareAgent & Long-Term Memory
How the model "remembers" across turns & sessions
About the Author
Ajay Walia
AI {IT Architect} focusing on local-first multi-agent AI engineering, zero-data-egress systems. Ideator, Creator and Executor on Curious Bit.
Keep Reading

LLMs Are Probability Engines, Not "Thinkers"
What ChatGPT and Claude actually are under the hood — a plain-English explainer of next-token prediction, softmax, attention, and why hallucinations are inevitable. Beginner to intermediate, with interactive animations.
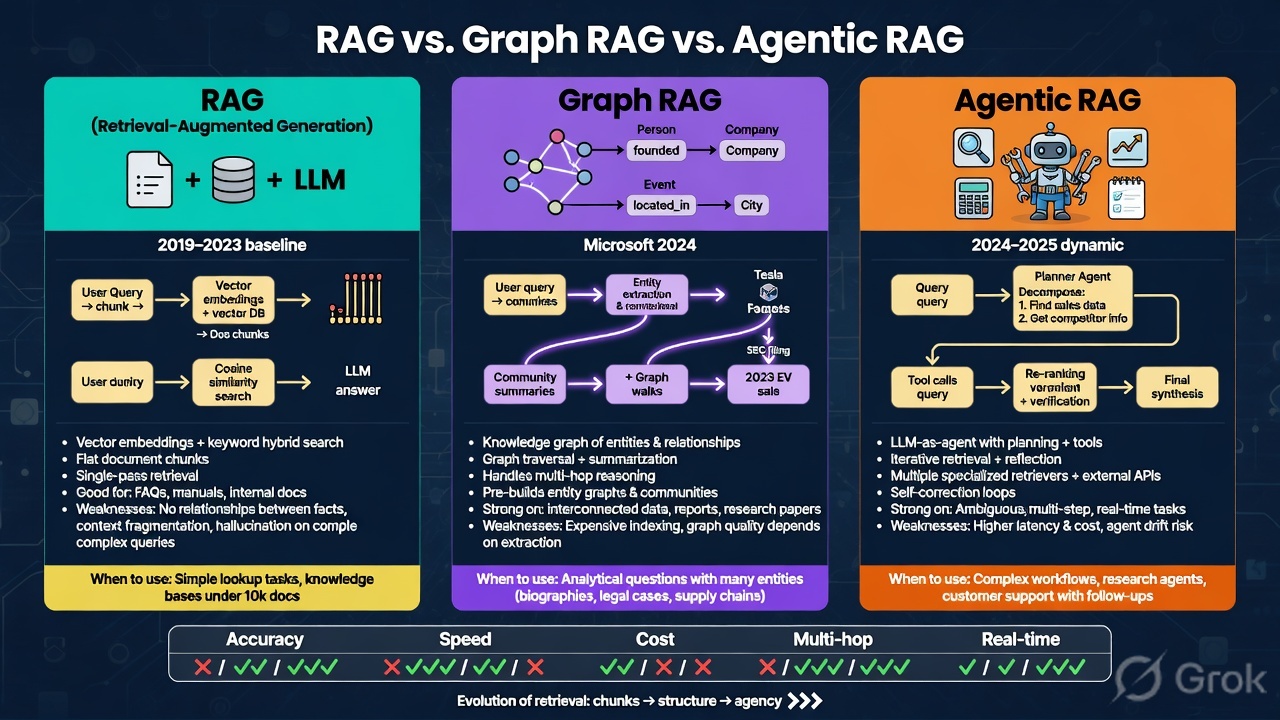
RAG, Graph RAG, Agentic RAG — and How to Make Any of Them 32× Memory Efficient
A visual breakdown of three RAG architectures — when each one wins, where it breaks down, and how binary quantization can shrink the vector index by 32× without changing the architecture you picked.

From FTEs to Agentic Workflows — Reshaping Infrastructure Outsourcing
A six-minute executive briefing on the architectural and commercial shift underway in Indian infrastructure outsourcing. Where the industry sits on the automation maturity curve, why the incentive conflict is harder than the technology, and what one fictional 80,000-endpoint bank account looks like over a 24-month rollout. Companion to the long-form analysis.