LLMs Are Probability Engines, Not "Thinkers"
What ChatGPT and Claude actually are under the hood — a plain-English explainer of next-token prediction, softmax, attention, and why hallucinations are inevitable. Beginner to intermediate, with interactive animations.
You've used ChatGPT. You've heard the word "AI" a thousand times this year. But here's something almost nobody explains clearly: the thing powering these tools is not intelligent in any human sense. It doesn't think. It doesn't understand. It doesn't have goals.
It is, at its core, a very sophisticated next-word predictor — a probability engine trained on the vast majority of text the internet has ever produced. Once you understand this, everything else — its strengths, its failures, its weirdness — clicks into place.
01 —What ChatGPT and Claude actually are
The term "Artificial Intelligence" conjures images of something that thinks, reasons, and understands — a mind in a machine. That framing is compelling, but misleading when applied to today's large language models (LLMs).
What you're actually talking to is an autoregressive probabilistic model. Every word it generates is the result of asking one question, over and over again:
That's it. Do that billions of times on internet-scale text, and you get something that looks uncannily like reasoning. But it is, fundamentally, pattern matching at extraordinary scale — not understanding, consciousness, or genuine intelligence.
| What you see | What's actually happening | The catch |
|---|---|---|
| It "reasons" | Pattern-matches reasoning traces from training data | Breaks on genuinely novel problems |
| It "knows facts" | Recalls high-frequency statistical associations | Hallucinates on rare edge cases |
| It's "creative" | Samples from learned creative pattern spaces | Derivative — remixes, doesn't invent |
| It has "opinions" | Outputs tokens shaped by training + alignment | No actual beliefs internally |
02 —The one job every LLM does
Let's make this concrete. Below is a live simulation of next-token prediction. Press "Predict next token" and watch the model pick the next word based on probability scores.
Notice the bars: each candidate word gets a probability score. The model doesn't "decide" in any human sense — it samples from this distribution. The highest-probability word is chosen most often, but not always. That's where both creativity and errors come from.
03 —The probability formula
Here's the mathematical heart of it. Hover each term for a plain-English tooltip, then press the button to reveal the full breakdown piece by piece.
Plain English: "Given everything typed so far, and everything the model learned during training, what is the probability of each possible next word?" The model scores every word in its vocabulary — 50,000+ words — and softmax turns those raw scores into probabilities that add up to exactly 1.0.
04 —Softmax: raw scores → probabilities
The model internally produces a raw score (called a logit) for every possible next word. Logits can be any number — positive, negative, large, small. They're not probabilities yet. The softmax function converts them into a clean distribution. Press the button to watch the transformation.
Notice: even the most negative logit still gets a small non-zero probability after softmax. The model never completely rules anything out — it just makes some words astronomically unlikely. This is partly why LLMs occasionally produce bizarre outputs: a 0.001% token still gets picked sometimes.
05 —How it learns: cross-entropy loss
During training, the model sees a sentence with the last word hidden and makes a prediction. The training algorithm asks: "How wrong were you?" The measure of wrongness is cross-entropy loss.
The formula: ℒ = −log P(correct word). If the model assigns 100% probability to the right word, loss = 0. If it assigns 1%, loss is very high. Drag the slider to see this in action.
P("lazy"): 0.23
ℒ = −log(0.23)
ℒ = 1.47
High loss → big update
06 —The Transformer: the machine inside
The specific architecture that makes modern LLMs work is called the Transformer, introduced in a landmark 2017 Google paper. Every major LLM today — GPT-4, Claude, Gemini, Llama — is built on this design.
A Transformer processes your text through many stacked layers. Each layer has two main components:
Feed-Forward Network — A dense neural network that processes each token's information independently, after attention has been applied.
A large model like GPT-4 stacks around 96 of these layers. With enough layers, parameters, and training data, emergent abilities appear — code generation, translation, basic reasoning — that nobody explicitly programmed. They fall out of the math at scale.
07 —Self-attention: every word watches every word
Before the Transformer, AI models processed text word by word in sequence, making it hard to connect things far apart in a sentence. Self-attention solves this by letting every word simultaneously evaluate its relationship to every other word. Click a word to see its attention weights.
08 —How text is actually generated
When you press Send in any AI chat app, here is exactly what happens:
- Tokenization — Your message splits into tokens (subwords). "unbelievable" → ["un","believ","able"].
- Embedding — Each token becomes a high-dimensional vector capturing meaning and position.
- Forward pass — Vectors flow through all Transformer layers. Attention and feed-forward happen, repeatedly.
- Logits → Probabilities — The final layer scores every vocabulary word. Softmax converts to probabilities.
- Sampling — One word is chosen based on those probabilities.
- Repeat — That word is appended and the whole process runs again until the response is done.
09 —Temperature: controlling randomness
When sampling the next word, you can control how random the selection is with a parameter called temperature. Drag the slider to see how it reshapes the probability distribution in real time.
Low temperature (e.g. 0.2) makes the model deterministic — it almost always picks the top word. High temperature (e.g. 2.0) flattens the distribution, giving unusual words a real chance. Most production systems run between 0.7 and 1.0.
10 —Why it sometimes lies (hallucinations)
One of the most misunderstood LLM behaviors is hallucination — when the model confidently states something false. This isn't a bug to be patched away. It's a direct consequence of the architecture.
The model has no internal truth checker. No access to the real world. It only knows: what sequence of words tends to follow this sequence of words? When asked something rare or obscure, the model fills the gap with statistically plausible text — which may be completely wrong.
11 —Key limitations to know
Understanding these isn't pessimism — it's how you use these tools well.
12 —What's next
The probability-engine core remains — but researchers are building powerful layers on top. RAG (Retrieval-Augmented Generation) gives the model access to real documents at query time, dramatically reducing hallucination on factual tasks. Agentic systems let LLMs use tools, execute code, and iterate on their outputs. Reasoning models generate long internal chains of thought before answering, improving performance on math and logic. And multimodal models extend the same probabilistic core to images and audio.
None of these change the fundamental nature of what an LLM is. They all sit on top of the same next-token prediction engine. Understanding that foundation is what makes you a sharper thinker about where this technology is — and isn't — going.
Video generated with Grok Imagine. Animations built with vanilla JavaScript.
Test what you read
Quick quiz

About the Author
Ajay Walia
AI {IT Architect} focusing on local-first multi-agent AI engineering, zero-data-egress systems. Ideator, Creator and Executor on Curious Bit.
Keep Reading

Aether, Grown Wild — The Implementation Journey (v2.6 → v2.8.2)
The second chapter of Aether: how a local-first team of IT architecture agents grew from a clean idea into a 13-agent, web-first, self-escalating system — and every bug that shaped it along the way.
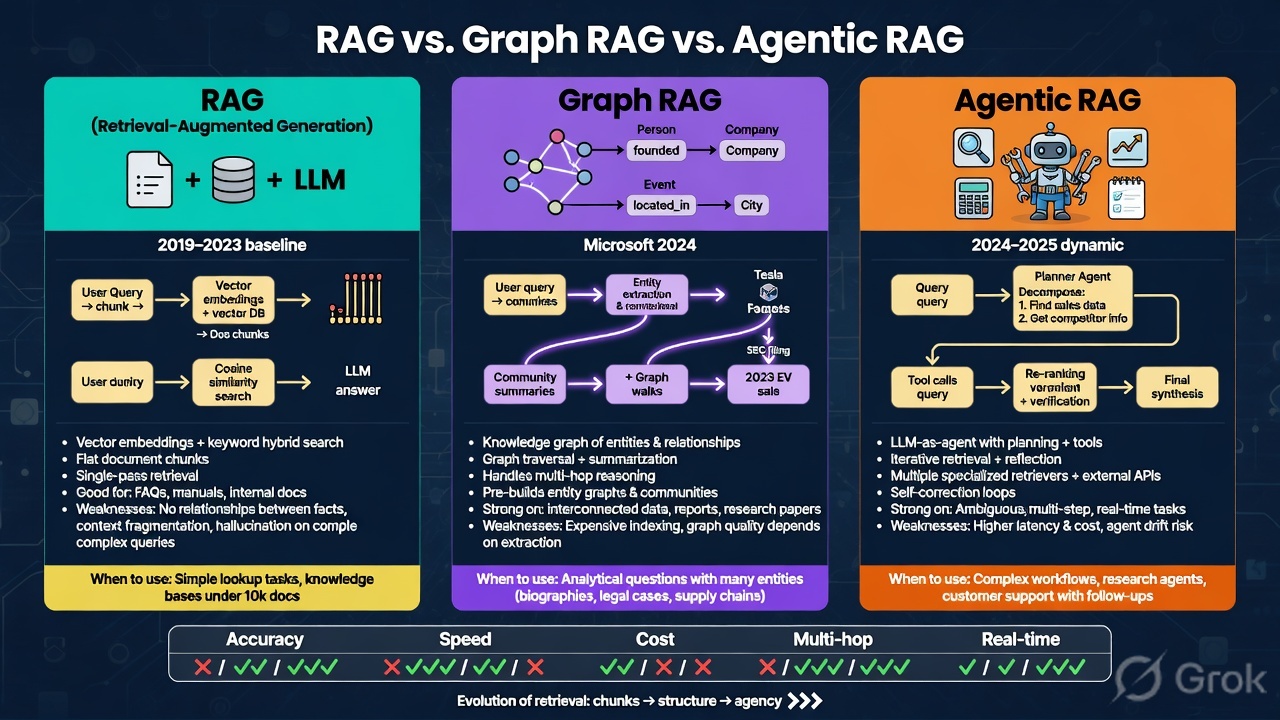
RAG, Graph RAG, Agentic RAG — and How to Make Any of Them 32× Memory Efficient
A visual breakdown of three RAG architectures — when each one wins, where it breaks down, and how binary quantization can shrink the vector index by 32× without changing the architecture you picked.

RAG Chatbot from indexed public documentation
A domain-specific Retrieval-Augmented Generation assistant built with LangChain, OpenAI embeddings and FAISS that answers questions about the GitHub REST API strictly from indexed public documentation. Week 15 graded mini-project of the IITM Pravartak Professional Certificate Programme in Agentic AI and Applications.