Knowledge Distillation: From Massive Models to Efficient Intelligence
How a large AI model teaches a small one everything it knows — and why that small model sometimes ends up smarter. A beginner-to-intermediate guide.

On this page
There is a scene you have probably seen in countless films: a master craftsman, decades of experience locked in his hands, patiently guiding a young apprentice. The master does not hand over a textbook. He transfers something richer — intuition, nuance, an understanding of why certain choices matter. The apprentice, unburdened by the master’s size and slowness, eventually moves faster and in some cases surpasses the teacher entirely.
Knowledge Distillation is that scene, rendered in mathematics.
Introduced formally by Geoffrey Hinton, Oriol Vinyals, and Jeff Dean at Google in 2015, Knowledge Distillation (KD) is a model compression technique where a large, expensive model — the teacher — transfers its learned intelligence to a compact, deployable model — the student. The student retains over 90% of the teacher’s accuracy while being up to 100× smaller and faster.
This article takes you from the intuition all the way through to the advanced variants that are reshaping AI deployment in 2026.
The Problem: Intelligence Is Expensive
Modern AI models are enormous. GPT-4 is estimated to contain over a trillion parameters. BERT-large has 340 million. These models achieve stunning accuracy — but they are cumbersome to deploy. Running a trillion-parameter model for every user query would require data centres the size of small cities.
The engineering instinct is to train a smaller model directly. But smaller models trained from scratch on raw data consistently underperform large ones. Why?
Because raw training data is hard. A cat photo labelled simply “cat” gives a small model very little to work with. A large model, however, does not just see “cat” — it sees a distribution of confidence across thousands of classes. “Cat: 0.92, Lynx: 0.06, Tabby: 0.02.” That probability distribution is enormously richer than the hard label.
Hinton called this richer signal dark knowledge — the information encoded in what the model almost predicted.
The Teacher-Student Paradigm
The core idea is elegant. Instead of training the student on raw labelled data, you train it to mimic the teacher’s output distribution.
You run every training example through the large teacher model. For each example, instead of a hard label (0 or 1), you collect the teacher’s full soft target — the probability it assigns to every possible class. You then train the student to produce those same soft probability distributions.
The student loss function becomes:
Loss = α × (cross-entropy with hard labels)
+ (1-α) × (KL divergence from teacher soft targets)
The blending weight α controls how much the student learns from the raw data versus the teacher’s guidance. In practice, a small α (more weight on teacher targets) is usually optimal.
Soft Targets and Dark Knowledge

Hard labels are binary. Soft targets are continuous. That difference is enormous.
Consider an image of a dog that slightly resembles a wolf. A hard label says “dog: 1, wolf: 0.” A teacher that has seen millions of examples says “dog: 0.84, wolf: 0.13, fox: 0.03.” That residual probability on wolf carries genuine information about the visual ambiguity in the image. The student trained on soft targets learns not just the answer, but the shape of uncertainty around the answer.
This is the dark knowledge. It lives in the tails of the distribution — the non-zero probabilities on wrong answers — and it makes the student dramatically more robust than one trained on hard labels alone.
Temperature: The Control Knob

Soft targets, by default, tend to be very peaked — the teacher is often highly confident in its top prediction, assigning 0.99 to the correct class and tiny residuals to everything else. At that extreme, the soft target is barely different from a hard label, and the dark knowledge disappears.
Hinton’s solution was temperature scaling. Before computing the softmax, you divide the logits by a temperature parameter T:
p_i = exp(z_i / T) / Σ exp(z_j / T)
At T = 1 (standard), outputs are sharp and peaked. At T > 1 (high temperature), outputs become softer and more spread, revealing the relative confidence structure across all classes.
During distillation, both teacher and student use the same elevated temperature (typically T = 3–5). This “warms up” the teacher’s output into a richer, more informative distribution for the student to learn from. After training, the student is deployed with T = 1.
The effect is striking. Higher temperatures expose more inter-class structure, giving the student a better map of the concept landscape rather than just a list of correct answers.
What Gets Transferred? Three Flavours of Distillation
Knowledge can flow from teacher to student in different ways. The research community has converged on three main categories:
Response-based distillation — the original Hinton approach. The student matches the teacher’s final output layer (soft targets). Simple, effective, widely used.
Feature-based distillation — the student is trained to match not just the final output but intermediate representations — specific layers or attention maps inside the teacher. This transfers how the teacher thinks, not just what it concludes. The trade-off is complexity: the teacher and student must have compatible architectures or an adapter layer is needed.
Relation-based distillation — the student learns to replicate the relationships between different training examples as the teacher sees them. If the teacher places cat images and dog images in nearby regions of its feature space, the student should too. This approach is particularly powerful for metric learning and few-shot tasks.
Advanced Variants
Multi-Task Distillation

Microsoft’s MT-DNN research showed that distillation composes naturally with multi-task learning. A teacher trained on nine different natural language tasks simultaneously was distilled into a single student model. The distilled MT-DNN outperformed the original on 7 of 9 GLUE benchmark tasks — pushing the single-model state of the art to 83.7%.
The insight: when a teacher has learned to generalise across many domains, its soft targets encode cross-task structure that a specialised student cannot discover on its own.
The Teacher Assistant Bridge
What happens when the teacher and student are so different in capacity that direct distillation fails? A very large teacher produces soft targets the tiny student simply cannot model well.
The solution is an intermediate Teacher Assistant (TA) — a medium-sized model that first distils from the large teacher, then acts as teacher to the small student. The TA bridges the capacity gap, giving the small student a more tractable target. Research has consistently shown this staged approach outperforms direct large-to-small distillation when the size gap is more than an order of magnitude.
When the Student Surpasses the Teacher

One of the most counter-intuitive findings in knowledge distillation is that the student can sometimes exceed the teacher.
The 2022 Symbolic Knowledge Distillation paper demonstrated this dramatically. The researchers distilled commonsense reasoning from GPT-3 (175B parameters) into a purpose-built commonsense model at 100× smaller size. The resulting student — COMET-DISTIL — outperformed GPT-3 on commonsense benchmarks.
How? The distillation process acted as a filter. Rather than transferring all of GPT-3’s knowledge, the researchers used a critic model to selectively distil only high-quality, high-confidence commonsense triples. The student was not burdened by GPT-3’s off-topic knowledge or low-confidence noise. It received a curated, concentrated version of the teacher’s relevant expertise.
This is the Renaissance apprentice story made literal: the student, given the master’s best knowledge and freed from the master’s constraints, eventually does better work.
Real-World Results
The numbers behind knowledge distillation are worth anchoring:
In Hinton’s original speech recognition experiments on a heavily used commercial system, a distilled single model matched the accuracy of a 10-model ensemble while requiring one-tenth the compute at inference time.
In the speech recognition benchmark specifically:
| Model | Frame Accuracy | Word Error Rate |
|---|---|---|
| Baseline (single model) | 50.9% | 10.9% |
| 10× model ensemble (teacher) | 61.1% | 10.7% |
| Distilled single student | 60.8% | 10.7% |
The student matches the ensemble at a fraction of the cost. This is the central promise of KD — and it has held up across vision, language, and speech for over a decade.
Why This Matters in 2026
Knowledge distillation is no longer a research technique. It is infrastructure.
Every major on-device AI model — the language models on your phone, the vision models in your camera, the wake-word detectors in your earbuds — was almost certainly distilled from a much larger cloud model. DistilBERT, MobileNet, and Whisper Tiny are all products of distillation.
The technique is also central to the LLM compression wave of the past two years. Models like Phi-3, Mistral Small, and Gemma were designed with distillation-aware training pipelines from the start. The goal: deliver GPT-4-class reasoning in a model small enough to run locally, privately, and cheaply.
And symbolic distillation — transferring knowledge as structured text rather than as neural activations — is opening entirely new territory, allowing language model intelligence to flow into specialised domain models that do not even share the same architecture.
A Practical Starting Point
If you want to experiment with knowledge distillation today:
For response-based KD in PyTorch, the training loop change is minimal — replace your standard cross-entropy loss with the blended loss described above and pass the teacher’s logits alongside the hard labels.
For NLP tasks, Hugging Face’s transformers library includes DistilBERT as a reference distilled model with its training recipe documented.
For vision, TorchVision’s knowledge distillation tutorial is the fastest on-ramp.
The key design decisions are: the temperature T (start at 4), the blending weight α (start at 0.5), and whether you need feature-based or response-based transfer (response-based first, feature-based if accuracy is still insufficient).
The master-apprentice metaphor is more than decorative. Knowledge distillation encodes a genuine pedagogical insight: that the richer the guidance a learner receives, the more efficiently it reaches competence. The hard labels of raw data are the equivalent of telling a student the answer. The soft targets of a teacher model are the equivalent of showing them how to think.
That distinction — answer versus thinking — is what makes knowledge distillation one of the most elegant ideas in modern machine learning.
Test what you read
Quick quiz

About the Author
Ajay Walia
AI {IT Architect} focusing on local-first multi-agent AI engineering, zero-data-egress systems. Ideator, Creator and Executor on Curious Bit.
Keep Reading
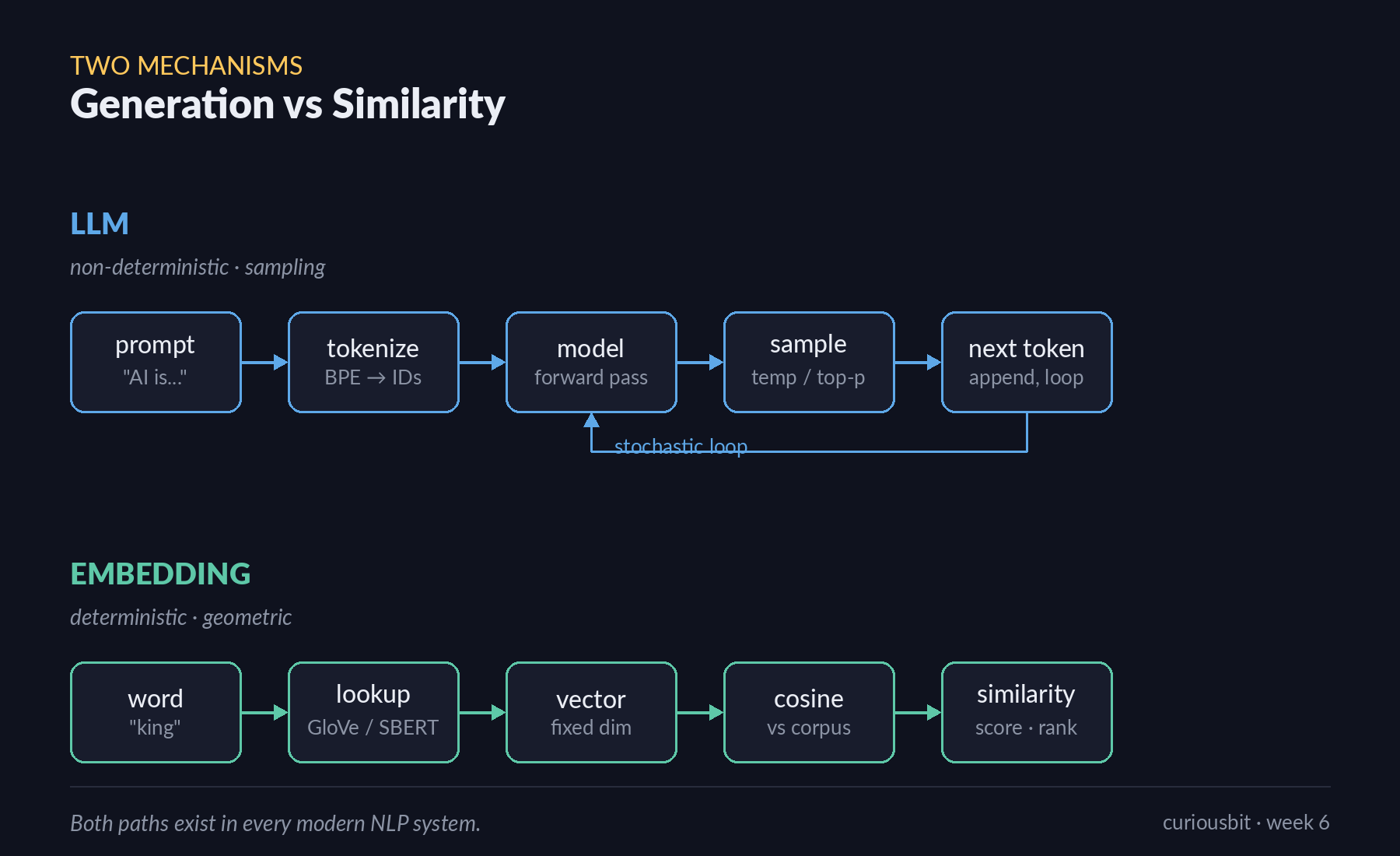
LLM & Embeddings — One Predicts Words. One Maps Meaning.
A walk through the two foundational mechanisms behind every modern NLP system — generative language models and similarity-based embeddings — using five hands-on exercises with Hugging Face and Gensim. Week 6 mini-project of the IITM Pravartak Professional Certificate Programme in Agentic AI.

Building with LLMs in 2026: The Framework Atlas
Choosing an LLM in 2026 is the least important decision in your stack. Here is the framework landscape every architect needs to navigate.

I Built, My Own Screenshot App for macOS (No More Clunky Screenshots)
How I got fed up with macOS native screenshot chaos, missed Greenshot from my Windows days, and built a lightweight menu bar screenshot app using Swift and Claude.