
⚡ Interactive
LLMs
Memory
Memory Management in LLMs
A structured hub on how large language models use, store, and optimize memory — from the bytes that hold model weights on a GPU to how an agent remembers across sessions. Pick a topic to dive in.
Field-tested explainers for digital workplace, artificial intelligence, cloud, security, automation, and enterprise operations.
A structured hub on how large language models use, store, and optimize memory — from the bytes that hold model weights on a GPU to how an agent remembers across sessions. Pick a topic to dive in.

What ChatGPT and Claude actually are under the hood — a plain-English explainer of next-token prediction, softmax, attention, and why hallucinations are inevitable. Beginner to intermediate, with interactive animations.
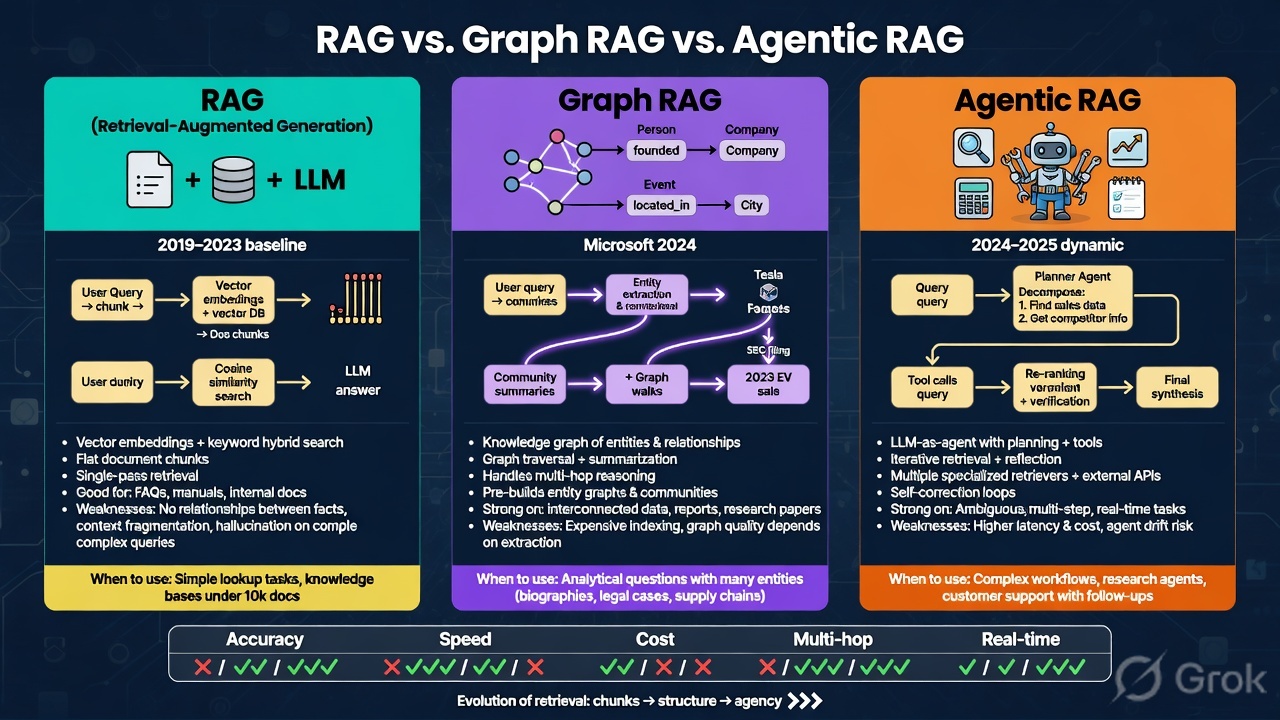
A visual breakdown of three RAG architectures — when each one wins, where it breaks down, and how binary quantization can shrink the vector index by 32× without changing the architecture you picked.

A six-minute executive briefing on the architectural and commercial shift underway in Indian infrastructure outsourcing. Where the industry sits on the automation maturity curve, why the incentive conflict is harder than the technology, and what one fictional 80,000-endpoint bank account looks like over a 24-month rollout. Companion to the long-form analysis.

AI is reshaping every job. The World Economic Forum, McKinsey, and peer-reviewed research agree on 17 skills that will define who thrives. Here they are — with how to build each one.

The 2017 paper that killed RNNs, invented the Transformer, and launched the modern AI era — explained for beginners and intermediates with 11 original manga panels.

Choosing an LLM in 2026 is the least important decision in your stack. Here is the framework landscape every architect needs to navigate.

How a large AI model teaches a small one everything it knows — and why that small model sometimes ends up smarter. A beginner-to-intermediate guide.

A beginner-to-intermediate field guide to the silicon powering modern AI. GPUs, TPUs, NPUs, CPUs, ASICs, FPGAs, edge chips and emerging architectures — what each is for, where you'll meet it, and how much it costs.