I Built a Team of IT Architects using LLM That Live on MacBook — Meet Aether
How I built Aether — a local-first, multi-agent AI system that runs 10 specialist IT architecture advisors on a single MacBook M5 Pro, with no cloud, no API costs, and zero data egress.
On this page
Every architect has felt this at some point. You are mid-design on a complex Azure landing zone, you need a sanity check on your FSLogix profile container sizing, and the fastest path to an answer is to ping a colleague who knows AVD cold — except it is 10pm, or they are in another timezone, or that colleague simply does not exist in your organisation.
I built Aether to fix that. It is a local-first, multi-agent AI system that runs a team of 10 specialist IT architecture advisors on a single MacBook Pro M5. No internet after setup. No API costs. No data leaves the machine. Just fast, cited, domain-grounded answers — available at 10pm when the deadline hits.
This is the story of how I built it, what the stack looks like under the hood, and what I learned along the way.
The Problem I Was Actually Solving
I have spent years in IT architecture — cloud, digital workplace, network, end-user computing, the works. Over that time I have accumulated a large personal knowledge base: AWS Well-Architected reviews, Intune compliance policy templates, AVD host pool sizing guides, Citrix NetScaler configurations, TOGAF artefacts, cloud adoption frameworks. The knowledge exists. The problem is retrieval — getting the right answer from the right domain quickly, without context-switching across six different documentation tabs.
Commercial AI tools are good at general answers. They are not great at answering “give me the exact OMA-URI path for configuring Windows Hello for Business through Intune on a hybrid-joined device for a tenant with MFA enforced at the Conditional Access layer.” That requires domain depth, and it requires knowing which documents to pull from.
I also wanted to explore a practical AI use case — not a demo, not a proof of concept, but something I would actually use daily. Aether became that experiment.
What Aether Is
Type: Local-First Multi-Agent AI System
Agents: 10 (3-tier hierarchy)
Model: Gemma 4 26B A4B (Q4_K_M) — single instance
Runtime: LM Studio → LangGraph → FastAPI → Gradio
Memory: ~43 GB of 64 GB unified (M5 Pro)
Egress: ZERO
API cost: ZERO
Aether is a local-first AI system that acts as a team of specialist architecture advisors — all running on your MacBook Pro M5. The headline technical trick: every one of those 10 advisors is the same Gemma 4 26B model, loaded once. What makes each advisor different is purely the system prompt it receives and the knowledge base namespace it retrieves from.
One model. Ten personas. Zero cloud.
The Three-Tier Agent Hierarchy
The agents are organised the way a real consulting firm would structure a team — from narrow specialist up to cross-domain strategist.

Tier 1 — Enterprise Architect (1 agent). Cross-domain strategy, TOGAF, Zachman, governance frameworks (GDPR, ISO 27001, HIPAA), technology investment decisions. This agent can read all knowledge base namespaces — it is the only one with that reach. The final escalation destination.
Tier 2 — Domain Architects (3 agents). Cloud Domain (multi-cloud strategy, FinOps, landing zones), Network Domain (SD-WAN, ZTNA, BGP, micro-segmentation), Digital Workplace Domain (Microsoft 365, VDI strategy, device management).
Tier 3 — Technology Architects (6 agents). AWS, Azure, GCP, Intune, AVD, Citrix. Each one is scoped tightly to its domain — deep, narrow, and fast.
The Stack, Component by Component
| Component | What It Does |
| Gemma 4 26B A4B (Q4_K_M) | The single model serving all 10 agents. MoE architecture — activates ~4–6B parameters per token. ~13 GB VRAM. |
| LM Studio | Local model server. OpenAI-compatible API on port 1234. Model stays resident in unified memory. |
| LangGraph | Orchestration graph — defines the multi-step query pipeline as a typed state machine. |
| LanceDB | Local vector database. One namespace (table) per agent. Fully file-based, no server process needed. |
| BAAI/bge-small-en-v1.5 | Embedding model. 384-dimensional vectors. Runs on the Apple Neural Engine — essentially free compute. |
| Redis | Session memory (24h TTL, rolling 3-turn window) and routing cache (1h TTL). |
| FastAPI + Uvicorn | REST API gateway on port 8000. Full query/response model, session management, agent listing. |
| Gradio | Web chat UI on port 7860. Session management, source citations, escalation chain display. |
| Prometheus | Metrics: query counts, latency per agent, escalation rate. Useful for understanding usage patterns. |
| SQLite (audit.db) | Immutable audit trail. Every query logged before response is returned. Cannot be skipped. |
The full system sits comfortably in about 43 GB of the M5 Pro’s 64 GB unified memory — leaving 21 GB of headroom for the rest of the machine.
The “One Model, Ten Specialists” Trick
This is the part I get asked about most, because it sounds like it should not work.
Every agent in Aether is defined by a YAML manifest. That manifest specifies a system_prompt, a namespace (which LanceDB table to retrieve from), a temperature, and max_tokens. There is no model switching. There is no weight loading. The Gemma 4 26B A4B is loaded once by LM Studio and stays resident.
# agent_manifests/aws_technology_architect.yaml
agent_id: aws_technology_architect
display_name: "AWS Technology Architect"
tier: 3
parent_agent: cloud_domain_architect
namespace: aws_tech
temperature: 0.1
max_tokens: 2048
system_prompt: |
You are an AWS Technology Architect with deep expertise in the
AWS Well-Architected Framework, EC2/EKS/Lambda sizing, IAM policy
design, CloudFormation and CDK, GuardDuty, and cost optimisation.
You draw only from AWS-specific documentation and architecture
patterns. When answering, cite the source documents retrieved.
End your response with a new line: 'Confidence: X.XX' (0.00–1.00)
reflecting how well your knowledge base supports this answer.
Why does this work? Because Gemma 4 26B A4B is a Mixture of Experts model. It routes each token through specialist sub-networks internally — activating only about 4–6 billion parameters per inference pass, despite having 26 billion total. The practical result: it runs at near 5B speed while retaining the reasoning breadth of a much larger dense model. A single loaded instance can faithfully adopt both a narrow Citrix specialist persona and a broad enterprise strategy persona, because the MoE routing shifts for each.
The other half of the trick is the knowledge base. Each Tier 3 agent retrieves only from its own LanceDB namespace. The AWS agent never sees a Citrix document. The Intune agent never sees a GCP architecture guide. Domain knowledge is isolated by design — which means the model cannot hallucinate across domain boundaries, because the retrieval context does not cross them.
Confidence-Driven Escalation
The escalation mechanism is the design decision I am most proud of.
Every agent is instructed to append a confidence score to its response — a float between 0.00 and 1.00 representing how well its retrieved knowledge supports the answer. The orchestrator reads that score via regex. If it falls below 0.7 and the agent has a parent tier defined and that parent has not already been tried, the system automatically escalates.
Query: "Give me a multi-cloud strategy covering Azure, AWS, GCP, AVD, and Citrix with network segmentation"
→ Routed to: aws_technology_architect
→ Confidence: 0.41 (below 0.7 threshold)
→ Escalate to: cloud_domain_architect
→ Confidence: 0.63 (still below threshold)
→ Escalate to: enterprise_architect
→ Confidence: 0.88 ✓
Response appended with escalation chain for full transparency.
The response shown to the user includes the full escalation path — which level of expertise produced the final answer. This matters in enterprise contexts. It is the difference between “the AI said so” and “the enterprise-level advisor produced this after the technical specialist’s knowledge was insufficient.”
The elegance here is that the model participates in its own routing decision. The orchestration does not need a separate classifier to judge answer quality — the model tells you its own confidence, and the system acts on it.
The 7-Step Query Pipeline
Every query passes through a typed LangGraph state graph. The state object — AetherState — carries everything between nodes: query, session ID, agent manifest, RAG results, conversation history, messages, response, confidence score, escalation flags, and escalation chain list.
01 — ROUTE. A keyword scanner maps the query to the best-fit agent, checking Tier 3 rules first (most specific), then Tier 2, then Tier 1 as catch-all. Redis caches route results for one hour, so repeated queries on the same topic skip the scan entirely.
02 — RETRIEVE. Semantic search against that agent’s LanceDB namespace — top-5 chunks returned. Documents were ingested at 500-word chunks with 50-word overlap, embedded into 384-dimensional vectors by BAAI/bge-small-en-v1.5 running on the Apple Neural Engine.
03 — HISTORY. The last three message pairs (six messages) are loaded from Redis for the session. This gives conversational continuity without letting the context window balloon.
04 — BUILD. The message payload is assembled: system_prompt + RAG documents + history + current query. The confidence instruction is appended here.
05 — LLM. The assembled payload hits LM Studio on port 1234. The orchestrator extracts the confidence score from the response text via regex before passing the response forward.
06 — ESCALATE (conditional). If confidence is below 0.7, a parent agent exists, and it has not already been tried this turn — swap in the parent’s manifest and loop back to step 02 with fresh retrieval against the parent’s namespace.
07 — FINALISE. The turn is saved to Redis. The SQLite audit record is written. The escalation chain annotation (if any) is appended to the response. Result returned to the user.
Knowledge Isolation — The Anti-Hallucination Architecture
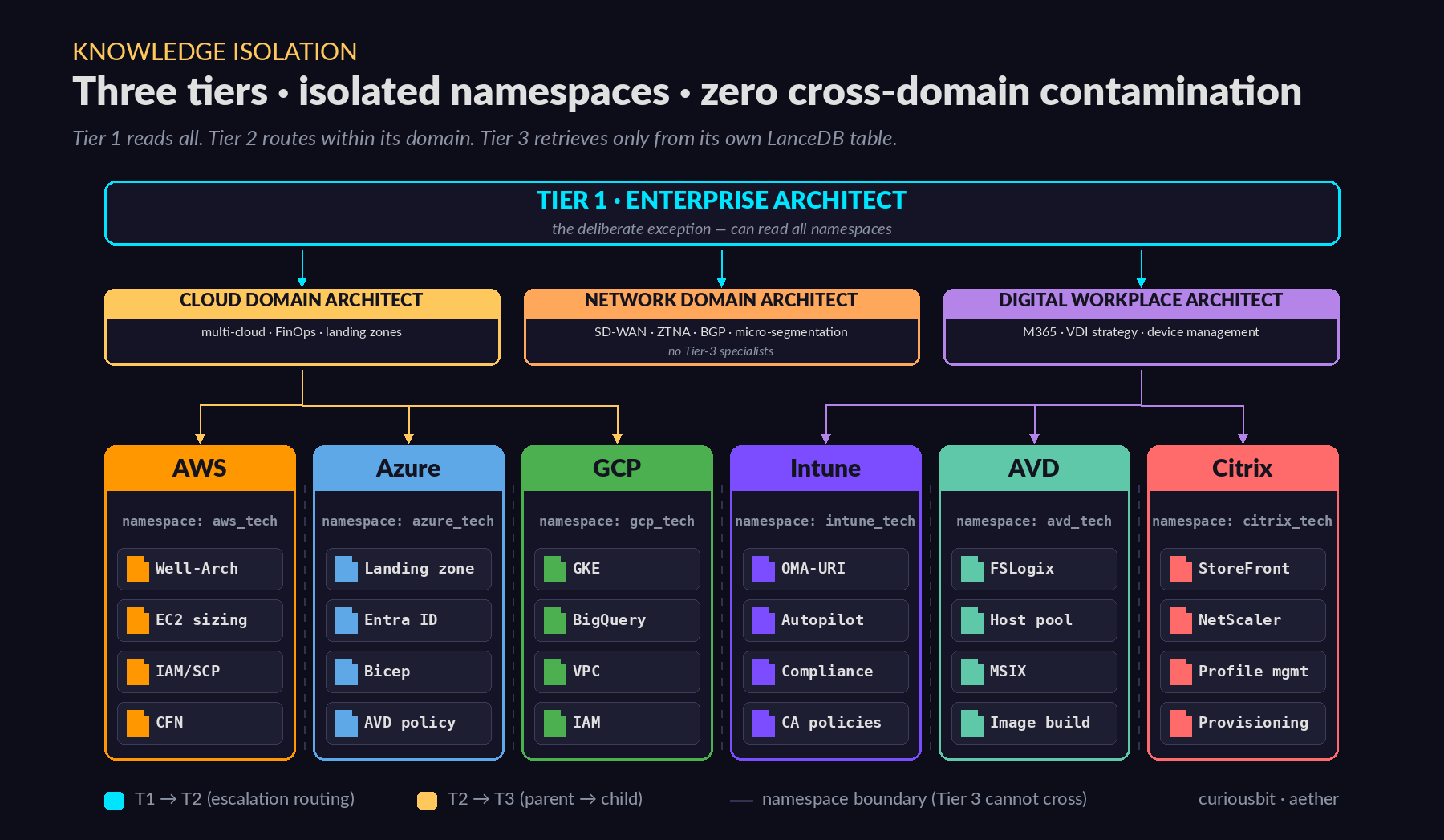
One of the most practical decisions in Aether’s design is namespace isolation. Each Tier 3 agent retrieves only from its own LanceDB table. The AWS agent’s retrieval context will never include a Citrix StoreFront configuration guide — because those documents simply do not exist in its namespace.
This matters more than it might seem. A common failure mode in RAG systems is cross-domain contamination — where retrieval pulls in tangentially related content from a different domain, and the model confabulates a plausible-sounding but wrong answer by blending the two. Namespace isolation eliminates this at the architectural level.
The Enterprise Architect at Tier 1 is the deliberate exception — it can query all namespaces, because cross-domain synthesis is exactly what it is built for.
The Audit Trail — Because Enterprise
Every single query is written to audit.db (SQLite) before the response is returned. The record includes: timestamp, session ID, query text, agent used, confidence score, escalation chain, and sources cited. The audit write is wrapped in error handling so that a database failure never blocks the main query flow — but the log is never optional.
# Simplified from the finalise node
audit_record = {
"timestamp": datetime.utcnow().isoformat(),
"session_id": state["session_id"],
"query": state["query"],
"agent_id": state["agent_id"],
"confidence": state["confidence"],
"escalation_chain": json.dumps(state["escalation_chain"]),
"response_length": len(state["final_response"])
}
db.execute("INSERT INTO audit_log VALUES (:timestamp, :session_id, ...)", audit_record)
For a system giving architecture recommendations — decisions that feed into multi-million dollar cloud commitments — having an immutable audit trail of what was asked, what agent answered, at what confidence level, via what escalation path, is not a nice-to-have. It is the thing that makes it organisationally defensible.
What It Can Actually Do
$ aether query "Right-size EC2 instances for a memory-intensive Java application"
$ aether query "Configure FSLogix profile containers for 500 AVD users"
$ aether query "Zero-trust network architecture for 5,000 remote employees"
$ aether query "Cloud adoption roadmap for a financial services firm"
$ aether query "Intune compliance policy for iOS BYOD — hybrid-joined, MFA enforced"
The depth per domain is real. The Intune agent knows OMA-URI paths, Graph API commands, Autopilot profiles, and licensing requirements — because those are the documents I ingested into its namespace. The AVD agent knows host pool design, FSLogix sizing, MSIX app attach, and session host scaling plans. The knowledge base is only as good as what you put into it — but that is also the point. This is my architecture knowledge, curated, searchable, and queryable at any hour.
What I Learned Building This
Prompt engineering IS the architecture. In a system like this, the YAML manifest is the agent. The difference between a brilliant AWS specialist and a generic AI assistant is entirely in what the system prompt says and what documents back it up. Getting those prompts precise, domain-bounded, and calibrated for the right temperature took longer than any of the code.
MoE models are underrated for local multi-agent work. The choice of Gemma 4 26B A4B over a dense model was the right call. You get reasoning breadth comparable to a much larger model at the inference cost of a small one, on hardware that most architects already carry.
Confidence as a first-class citizen. Asking the model to self-assess and surface that score is one of the highest-value things I added. It makes the system honest — and it drives the escalation logic that makes the team metaphor actually work.
Namespace isolation is a practical hallucination brake. Not a theoretical one. In the first version of Aether, all documents lived in a single namespace. Cross-domain contamination was visible and annoying. Splitting into per-agent namespaces fixed it immediately.
Audit trails are not overhead — they are the point. Every enterprise AI deployment should have one. Building it into the core pipeline from day one changes how you think about what the system is producing.
What Is Next
Aether v2.6 is a working, daily-use system. The next version I am working toward adds a web-based ingestion UI (so loading new documents does not require touching the ingest script), structured output for architecture decision records (ADRs) in a consistent format, and inter-agent communication — where a Tier 3 agent can proactively pull context from a peer rather than waiting for the escalation chain to activate.
I built Aether because I wanted a team. It turns out a team was always available — it just needed the right prompts and a local model to bring it to life.
Have questions about the stack or want to see specific parts of the implementation? Drop a comment or reach out on LinkedIn.

About the Author
Ajay Walia
AI {IT Architect} focusing on local-first multi-agent AI engineering, zero-data-egress systems. Ideator, Creator and Executor on Curious Bit.
Keep Reading

Building with LLMs in 2026: The Framework Atlas
Choosing an LLM in 2026 is the least important decision in your stack. Here is the framework landscape every architect needs to navigate.

Attention Is All You Need — The Paper That Rewired AI
The 2017 paper that killed RNNs, invented the Transformer, and launched the modern AI era — explained for beginners and intermediates with 11 original manga panels.

I Built, My Own Screenshot App for macOS (No More Clunky Screenshots)
How I got fed up with macOS native screenshot chaos, missed Greenshot from my Windows days, and built a lightweight menu bar screenshot app using Swift and Claude.