Building with LLMs in 2026: The Framework Atlas
Choosing an LLM in 2026 is the least important decision in your stack. Here is the framework landscape every architect needs to navigate.

On this page
Four years after LLMs entered the mainstream, the single most common mistake I see architects make is spending most of their decision energy on the model. Which frontier model? GPT or Claude or Gemini? The model choice matters — but it is one decision out of roughly fifteen, and it is far from the most consequential one.
Building an LLM-powered system in 2026 is an architecture decision made across a stack of competing frameworks, each solving a well-posed problem at a specific layer. I spent several months mapping that landscape as a practitioner — the result is a 73-page whitepaper I call the Framework Atlas. This post distils it into the five things I think every architect, engineer, and senior IT leader should know before picking a single tool.
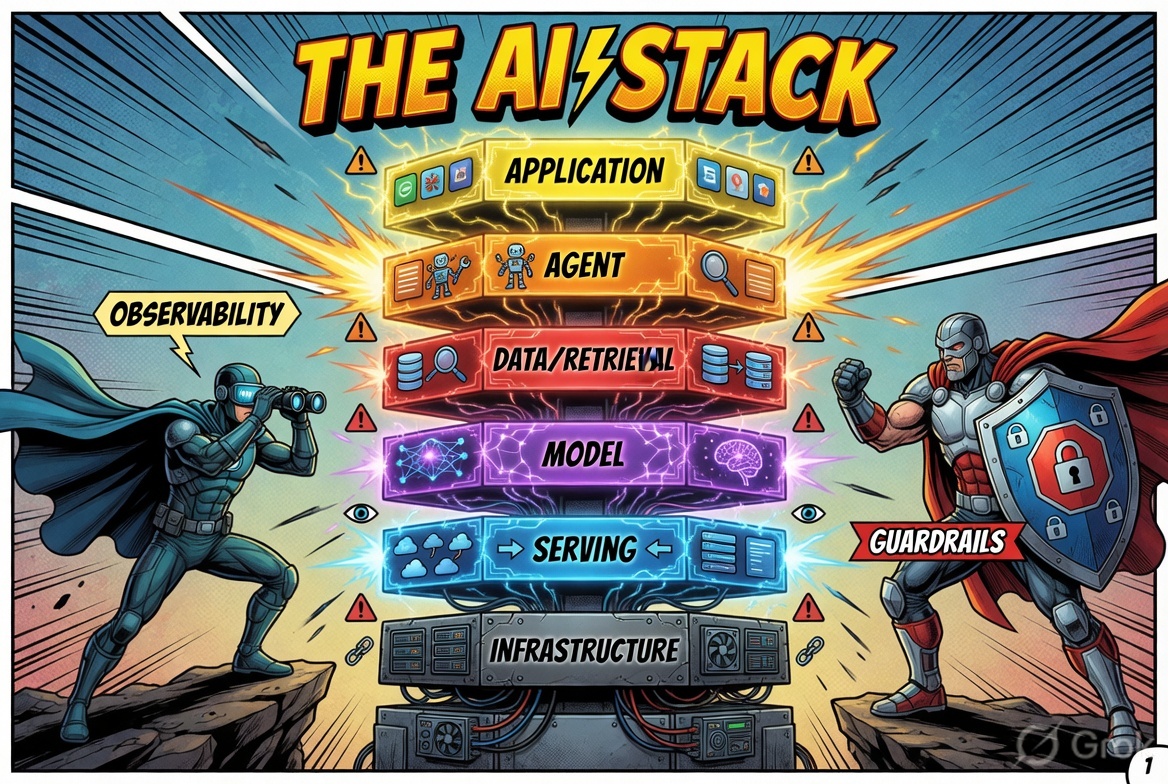
The Stack Has a Shape
There is no single AI stack, but there is a canonical shape. Every non-trivial production LLM system — whether a support chatbot, a document search engine, or a multi-agent workflow — is a composition of six layers:
Application layer. The surface your user interacts with. LangChain is the default; Semantic Kernel is the Microsoft-native choice; CrewAI leads when the app itself is agentic.
Agent layer. When a single LLM call is not enough — when the system needs to plan, call tools, or coordinate among multiple agents — this layer provides the loop. LangGraph is the most production-grounded option in 2026.
Data / retrieval layer. The memory of your system. LlamaIndex leads on orchestration; Weaviate, Pinecone, and Chroma compete at storage, each tuned for a different operational profile.
Model layer. The foundation models themselves. This layer is increasingly commoditised. The most important design decision here is not which model you start with — it is whether you can swap it without rewriting the layers above.
Serving / inference layer. How you turn a model into an endpoint. vLLM dominates throughput-bound workloads; BentoML packages models into clean APIs for teams that want to think about models, not infrastructure.
Infrastructure layer. Kubernetes, Docker, cloud, on-prem. Every framework choice depends on where you can actually deploy.
Wrapped around all six layers are three concerns that have become non-negotiable since 2024: observability and evaluation, fine-tuning and training, and guardrails and safety. If your system design has no answer for any of these three, it is under-designed. Ignoring them does not eliminate the risk — it just defers it until something breaks in production.
The Abstraction Trap
Every framework in the atlas is catalogued against eleven attributes, but the one architects under-weight most consistently is abstraction level — how much code you write versus how much the framework decides for you.
LangChain’s high abstraction makes the first demo fast and the tenth production fix slow, because you are debugging through someone else’s default decisions. FAISS’s low abstraction costs more lines but yields fewer surprises at 3am.

The operational signal: match abstraction to team seniority. Junior teams over-value high abstraction; senior teams over-value low. A mixed team benefits from a medium default — and from making the choice explicitly rather than defaulting to whatever has the best GitHub star count.
Decision Heuristics That Actually Hold
Rather than optimising at each layer independently, the atlas maps common requirements to preferred framework combinations. These are the ones I have found most durable in practice:
| Requirement | Starting stack |
|---|---|
| Fast LLM prototype | LangChain + Chroma + OpenAI API |
| Enterprise-grade RAG | LlamaIndex + Weaviate + LangSmith |
| Multi-agent workflow | LangGraph (+ AutoGen for agent conversations) |
| High-throughput inference | vLLM + Ray Serve |
| Local / offline / on-prem AI | Ollama + FAISS + LangChain-local |
| Domain-specialised model | Axolotl (QLoRA) + vLLM + MLflow |
Two things stand out from this table. First, LangChain and LlamaIndex are not competitors — they compose cleanly, with LangChain at the application layer and LlamaIndex at the retrieval layer. Second, local inference is no longer an edge case. Ollama plus a Llama-3-class model is a realistic production option for regulated industries where data sovereignty is a hard constraint.

Agents Moved to Production — With Guardrails
In 2023, autonomous agents were mostly demos. By 2026, they are in targeted production use: triage, routing, research synthesis. What changed is not the models — it is the frameworks.
LangGraph’s state-machine model gives agents deterministic control flow: you declare states, transitions, and retry policies explicitly. AutoGen models multi-agent systems as conversations, which makes it remarkably expressive for critique-revise loops and planner-executor separations. The practitioner heuristic: for production agents, LangGraph. For multi-agent conversations, AutoGen. For lightweight document workflows, CrewAI.
The critical note: never deploy autonomous agents in production unless the failure cost is bounded. The agent should draft; a human should approve. The pattern that ships is almost always a hybrid — autonomy where the stakes are low, escalation where they are not.

Guardrails have crossed from afterthought to critical infrastructure in the same period. Prompt injection is the new SQL injection. Every production system needs an input guard, an output guard, and a policy layer between them. The minimum viable defense in 2026 is: input guard → LLM → output guard. Anything less is operating without a seat belt.
The 2026 Outlook: Three Trends Worth Designing For
Agents are becoming the compile target. LangGraph, AutoGen, and CrewAI are converging on a common abstraction — a loop over an LLM with tool use and state. Expect a future that looks like the deep learning layer in 2018: multiple frontend frameworks, one common runtime. Design your agent layer to be swappable.
Retrieval is eating search. Elasticsearch, Postgres, and OpenSearch all ship vector indexes now; Weaviate and Pinecone ship BM25. The primitives have converged. The differentiator is no longer features — it is operational maturity and the team’s ability to run the infrastructure. Hybrid retrieval (vector + keyword) is the production-safe default.
Guardrails are becoming infrastructure. Today they are a library you bolt on. In two years they will be a runtime — prompt injection detection, PII scrubbing, and policy enforcement applied by default to every model invocation, the way CORS and auth middleware is applied to every HTTP request today. Get ahead of this by treating your guardrails layer as critical infrastructure now, not as a compliance checkbox later.
A Practitioner’s Closing Note
Frameworks age faster than architectures. The stack shape you design today — application, agent, retrieval, model, serving, infrastructure — will still be valid in three years. The individual framework boxes you fill it with probably will not be. The single most important design invariant is swappability at each layer. Make the layer interfaces clean, keep the framework-specific code thin, and you will be able to move when the landscape shifts — and it will.
The full Framework Atlas (v4.0, April 2026) covers all ten framework categories in detail, including comparison tables, maturity radars, cost and latency envelopes, and four reference architectures with working code. It is available below.
Download the Framework Atlas — Building with LLMs v4.0 (PDF)

About the Author
Ajay Walia
AI {IT Architect} focusing on local-first multi-agent AI engineering, zero-data-egress systems. Ideator, Creator and Executor on Curious Bit.
Keep Reading

A Field Guide to AI Chips
A beginner-to-intermediate field guide to the silicon powering modern AI. GPUs, TPUs, NPUs, CPUs, ASICs, FPGAs, edge chips and emerging architectures — what each is for, where you'll meet it, and how much it costs.
LLM & Embeddings — One Predicts Words. One Maps Meaning.
A walk through the two foundational mechanisms behind every modern NLP system — generative language models and similarity-based embeddings — using five hands-on exercises with Hugging Face and Gensim. Week 6 mini-project of the IITM Pravartak Professional Certificate Programme in Agentic AI.

I Built, My Own Screenshot App for macOS (No More Clunky Screenshots)
How I got fed up with macOS native screenshot chaos, missed Greenshot from my Windows days, and built a lightweight menu bar screenshot app using Swift and Claude.