Aether, Rethought — The Shape Was Wrong All Along
Our first build mirrored the org chart. It was the wrong shape. Here's how five recognised agentic design patterns, scored against the same criteria, led to a hybrid recommendation — and what changes in v3.

On this page
Part III of the Aether series. Missed the first two? Start with Meet Aether (the build), then Aether, Grown Wild (what happened when it ran).
The story so far — one paragraph each
Part I: I built a 10-agent (later 13-agent) system that runs an entire team of IT architecture specialists on a single MacBook M5 Pro — one Gemma model, zero cloud, zero data egress. Every agent is just a YAML manifest: a different system prompt and a different knowledge-base namespace pointing at the same weights. The system escalates upward when confidence falls below 0.7.
Part II: That clean idea hit reality. The router was rebuilt twice, retrieval flipped from knowledge-base-first to web-first, and self-reported confidence was replaced by a formula the system computes. Thirteen agents, a live web allowlist, a computed confidence score, and a CHANGELOG.md in place of Git.
Part III (this one): The shape is wrong. The hierarchy that felt so natural — because it mirrors the org chart — turns out to optimise for the wrong things. I worked through five recognised ways to build an agentic AI system, scored each against the same criteria, and arrived at a recommendation that changes the architecture without throwing away anything we’ve built.
What we’re actually building
The output isn’t a chatbot. It’s a consulting deliverable — an architecture document advising how to run an IT transition. Every real client engagement spans multiple towers simultaneously: a move to Entra ID while modernising the network and shifting workloads to Azure touches Cloud, Network, Digital Workplace, and Security in the same breath. The value and the difficulty live in the cross-domain synthesis.

Where we started — the three-tier hierarchy
This is what Aether v2.x actually is. One model, thirteen agents, each differentiated only by system prompt and knowledge namespace. Work routes down the tree; low confidence escalates back up.
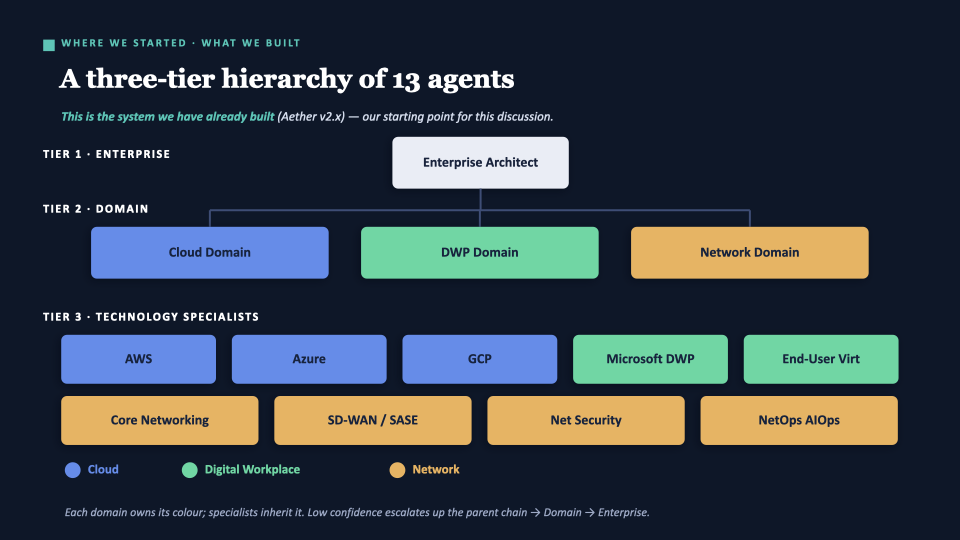
It was appealing for real reasons: it mirrors how a delivery organisation thinks, easy to explain to a client, and the RAG namespace-per-domain isolation is clean. But we copied an org chart into the control flow — and the next slide explains why that’s usually a trap.
The core insight — why the org chart is the wrong shape
This is the conceptual centre of the entire analysis. Everything that follows flows from these two points.

A strict tree only allows vertical movement — up to escalate, down to delegate. Real architecture work needs lateral collaboration. The AWS specialist can’t directly ask the Network specialist a question; it has to climb the entire tree and back down. That’s bureaucracy encoded in Python.
The second consequence is more fundamental: the deliverable is a workflow, not an organisation. Producing an architecture document is a consulting process with phases. The right structure for that process is a pipeline. We modelled the people first and the process second — we should have done it the other way round.
Five ways to build it
Rather than jump straight to a new design, I evaluated five recognised approaches against the same five axes: cross-domain capability, parallelism, auditability, simplicity, and fit for document generation.

Note the footer: RAG sits underneath all five approaches — they differ in control flow, not in whether they retrieve.
Approach 1 — Hierarchical / org-mirror
This is what Aether v2.x already is.
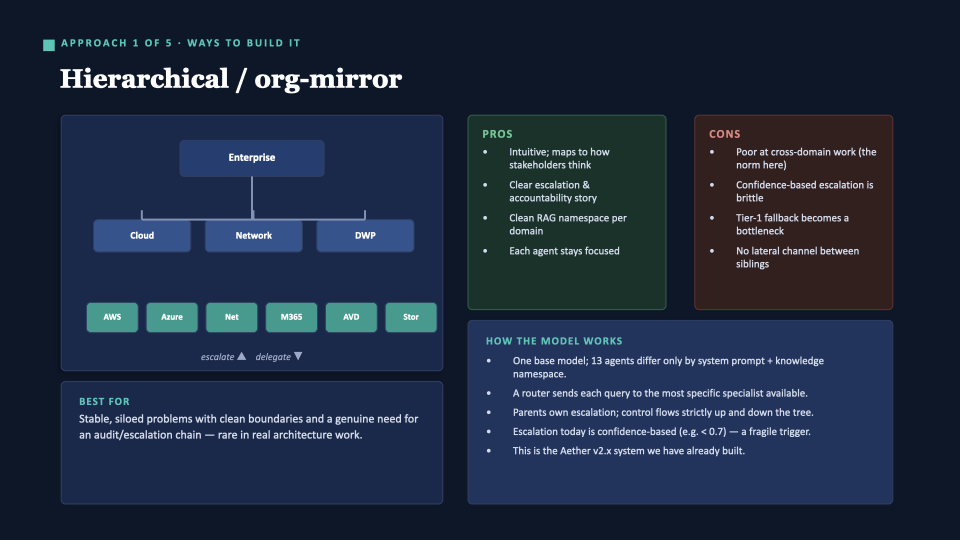
The pros are real — which is why we chose it. But the killer con: there is no sideways path. The AWS agent can’t ask the Network agent a question without escalating all the way up and back down. Also, escalation triggered by confidence scores sounds clean, but LLM confidence is unreliable — the trigger itself is shaky.
Verdict: Great for stable, siloed problems with a genuine audit chain. That is not what our engagements look like.
Approach 2 — Orchestrator + flat specialists
One orchestrator plans the task, fans it out to specialists running in parallel, then synthesises. Flat: adding a domain means adding one specialist — no re-tiering.
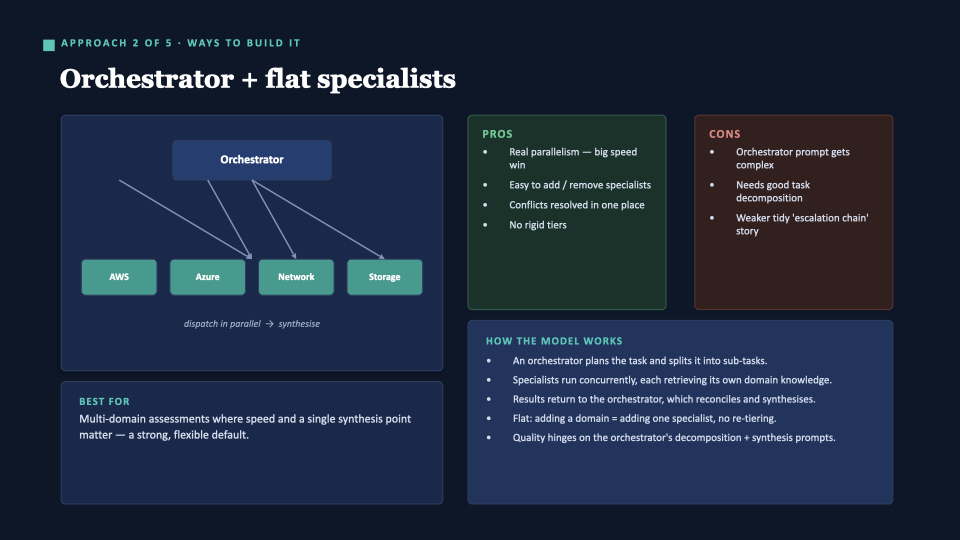
Verdict: A strong, flexible default. A piece of the recommendation.
Approach 3 — Workflow / pipeline (process-native)
Instead of organising by who, organise by the stages of producing the document: Discover → Assess → Design → Review → Assemble. Each stage maps to a section of the output. Human checkpoints slot between stages.
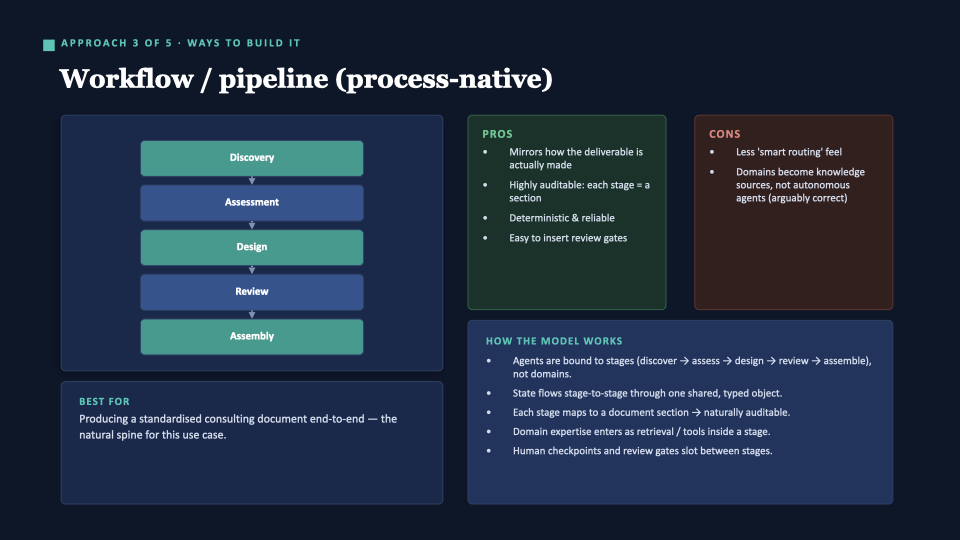
Verdict: This is the spine. The structure that mirrors how the deliverable is actually made. The so-called con — that domain experts become knowledge sources rather than autonomous agents — is arguably the correct framing.
Approach 4 — Blackboard / shared artifact
All agents read and write a common workspace — the evolving document. Strong on cross-domain consistency because there’s only one object. The hard part is concurrency control.
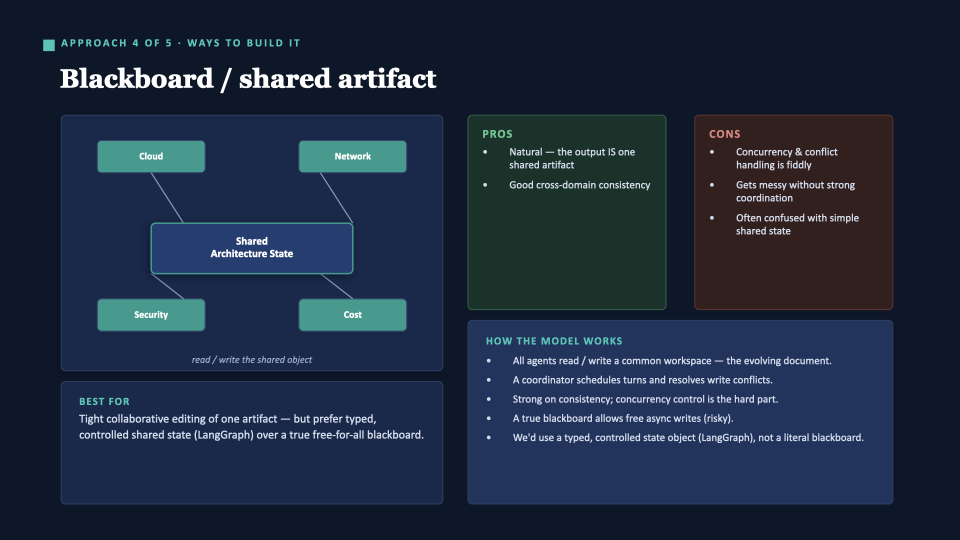
Key distinction: a true blackboard (free-for-all writes) is risky. A typed, controlled shared state object — which LangGraph gives us — keeps the benefit without the chaos. We use the controlled version.
Approach 5 — Single-agent baseline
One capable model. A lightweight router. Domain knowledge bases on demand. Simplest, cheapest, most reliable.
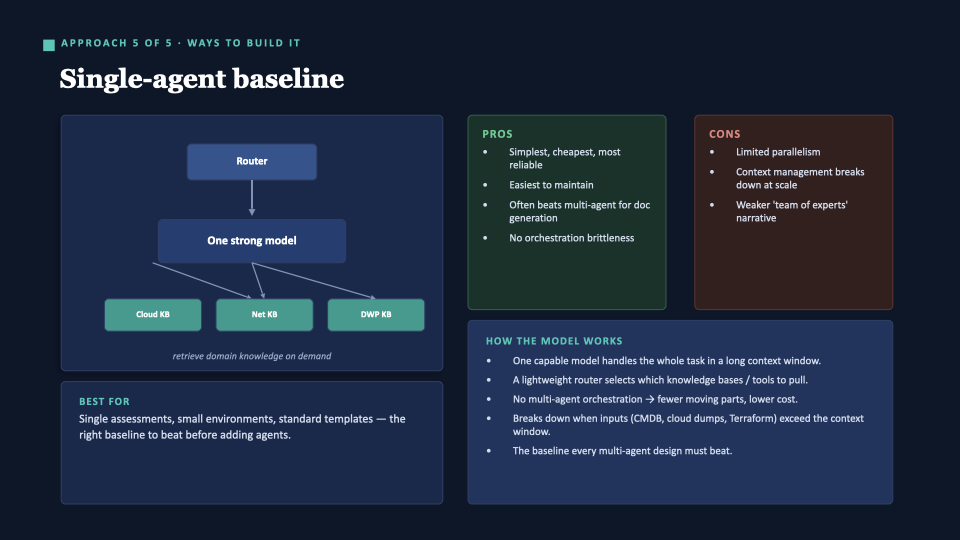
Verdict: The benchmark every fancier design has to beat. The real reason to decompose is information management — not model weakness. When CMDB exports, cloud inventories, and Terraform files all arrive together, no context window handles it cleanly.
The comparison
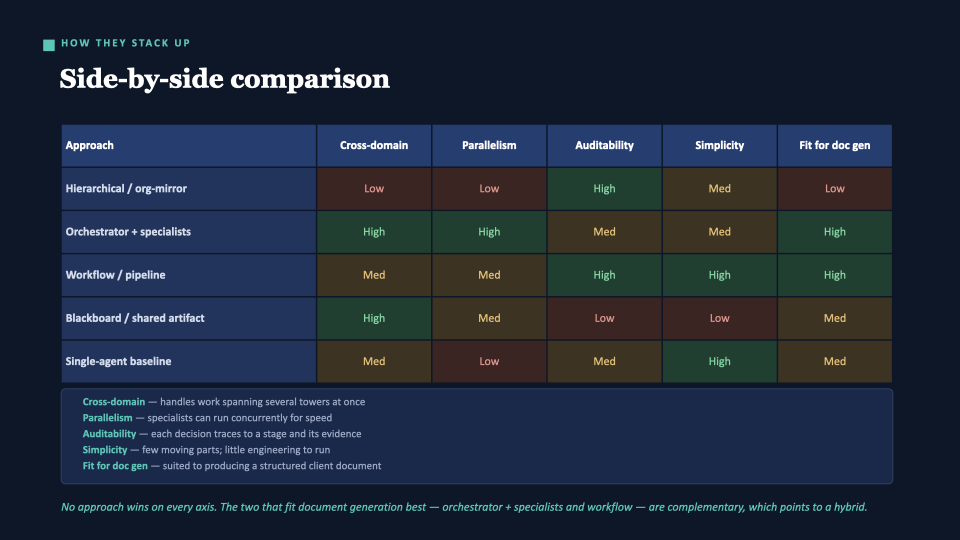
The table does the work. Our current design (Hierarchical) is weakest exactly where we need strength — cross-domain — while strong on auditability. The two approaches that score high on fit-for-doc-gen are complementary: strong in different places. That’s the bridge to the recommendation.
The recommendation — a hybrid
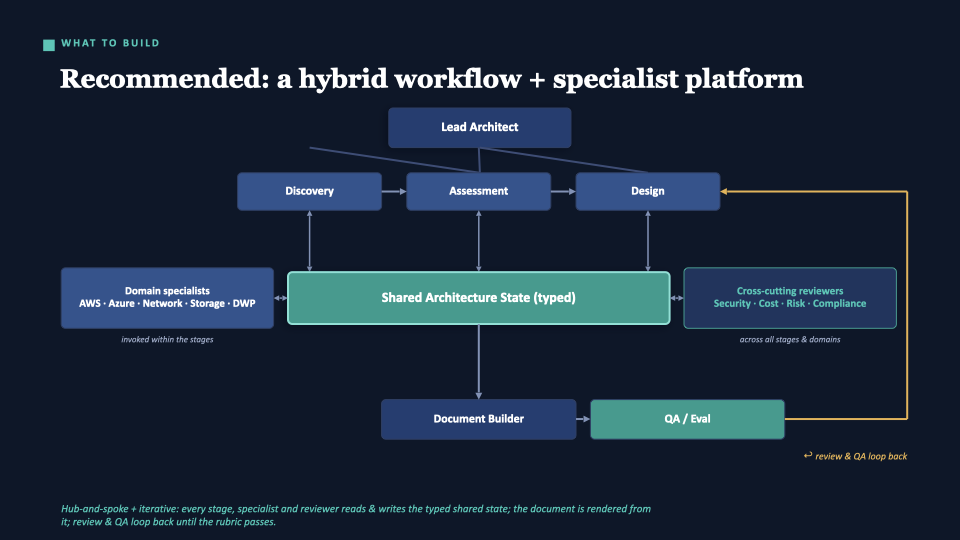
Not a ladder. A hub. The pipeline (Discovery → Assessment → Design) flows through a single typed shared state object. Domain specialists are invoked within stages — callable skills, not autonomous routing agents. Cross-cutting reviewers (Security, Cost, Risk, Compliance) act across all stages. QA can loop work back to Design or Assessment until the rubric passes.
How the model works

Three things to highlight:
- Parallel specialists write structured findings into one typed shared state — the single source of truth
- Arbitration is deterministic — fires on conflict, policy breach, or missing data, never on confidence scores
- The model is pluggable — local Gemma today, Claude/OpenAI/Gemini tomorrow, same knowledge, no rigid tree
Why this is the right call

The verdict, stated plainly: it’s the only option that handles cross-domain work with the auditability, governance, and evidence-traceability a client deliverable demands — at an acceptable, well-understood increase in build complexity.
The technology stack — nothing new to install

Every box in the stack is something we already run. The v3 work extends Orchestration and adds the governance/eval layer. This is not a rebuild.
The process — how a real engagement runs
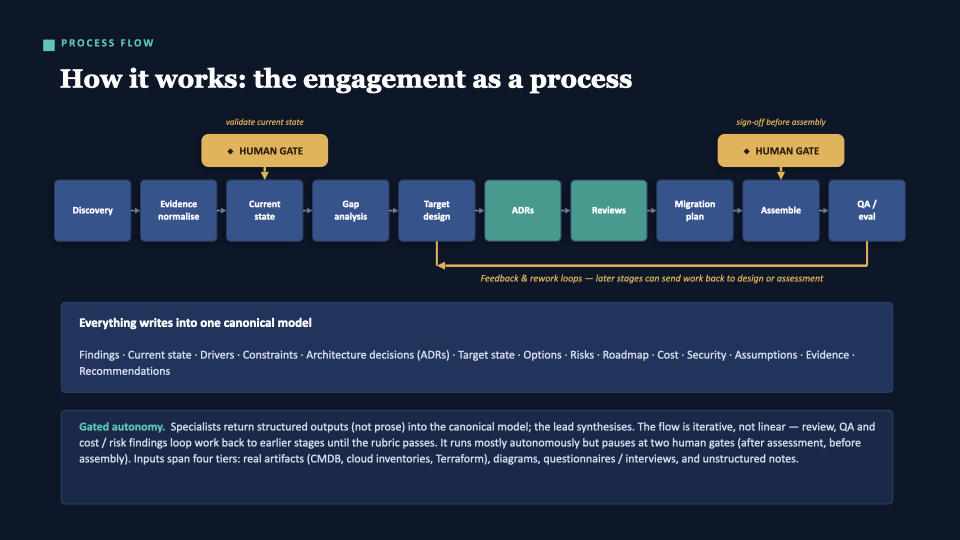
Two things to notice:
- Feedback arrows — review, QA, and cost/risk findings can send work back to Design or Assessment. It’s iterative, not a one-way pipeline.
- Human gates — after assessment and before assembly. An architect validates the current-state picture and signs off before the document is built. Gated autonomy, not full automation — which matters when the output carries liability.
The real hard problem — evidence quality

Every downstream recommendation carries the confidence level and assumptions set at this gate. No silent guessing. The system requests more data, logs gaps in an assumption register, or proceeds while explicitly stating its confidence level.
What flows through the system — the canonical Architecture State
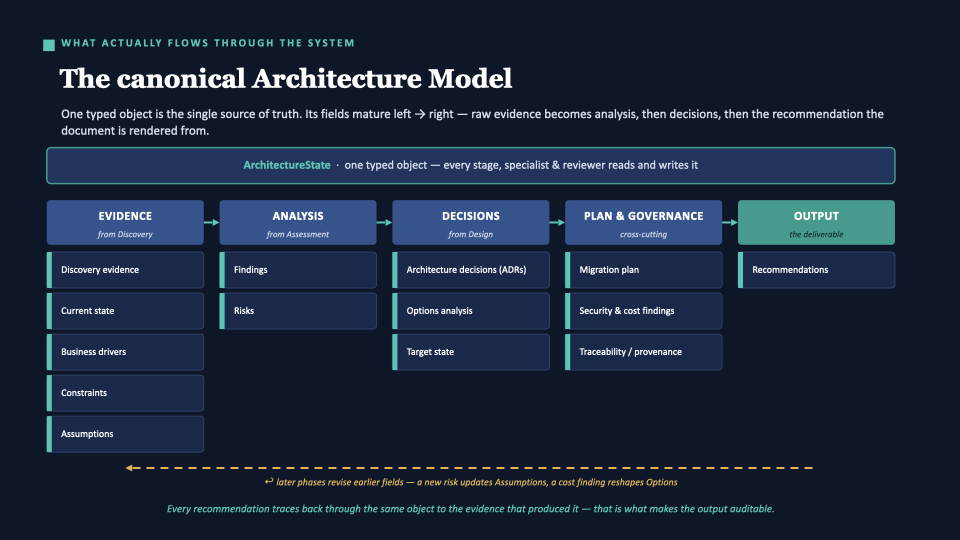
One typed object. Every stage, specialist, and reviewer reads from and writes to it. The document is rendered from it. Every recommendation traces back through the same object to the evidence that produced it — that traceability is what makes the deliverable auditable.
Lenses, not domains — where security and compliance live
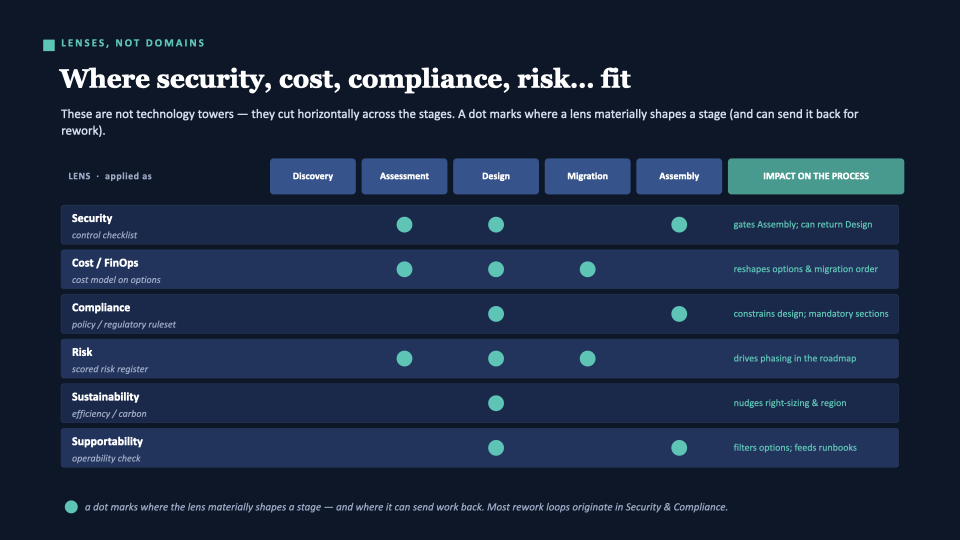
Security is a lens, not a domain. Same for Cost, Compliance, Risk, Sustainability, and Supportability. They aren’t towers sitting next to Cloud and Network — they cut horizontally across every stage. Most rework loops originate in Security and Compliance, which is exactly why they’re first-class cross-cutting reviewers.
Key design considerations

The most important reframe: we decompose for information management, not because the model is weak. That reframes the whole multi-agent debate. And arbitration fires on deterministic events — never on confidence scores. Every recommendation must trace to evidence.
Design decisions — where the build effort actually goes
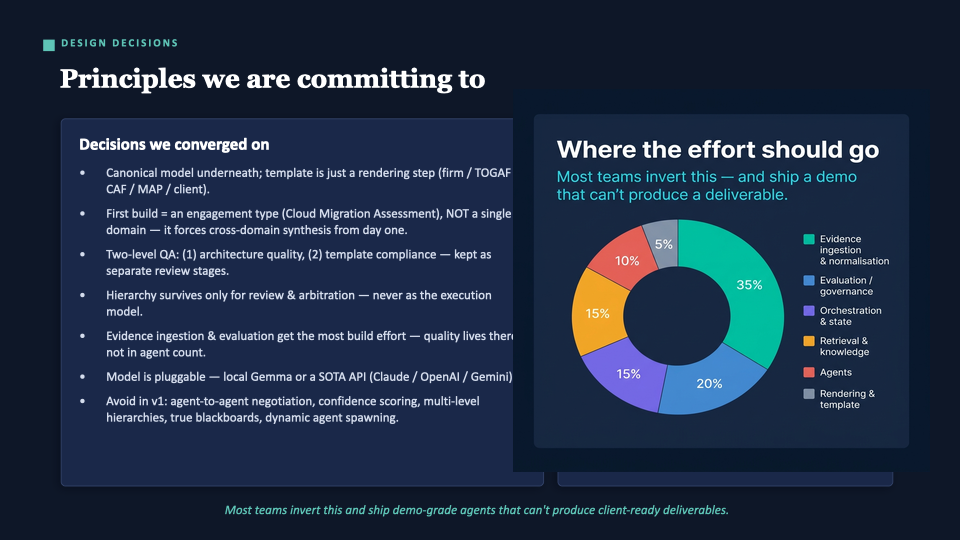
The effort allocation is the provocative bit. Only ~10% of build effort goes to the agents themselves. ~35% is evidence ingestion and normalisation. ~20% is evaluation and governance. Most teams invert these numbers — polished agents, no evaluation — and end up with a demo that can’t produce a deliverable a client would pay for. That’s the trap we’re avoiding.
Business value

The positioning: a consulting accelerator and quality platform — not a headcount-reduction play. The specific numbers (50–80% faster assessments, 60–90% less evidence-collection effort) are hypotheses to validate in a pilot, not measured results. They’re framed that way because that’s what earns trust.
Next steps

The sequencing matters: evidence ingestion and the QA rubric first, agent polish second. That’s where the quality actually lives.
The honest accounting
I built a hierarchy because it was intuitive. It is intuitive — it maps to how the organisation thinks, the escalation chain is easy to trace and audit, and it’s easy to explain to a client. Those are real advantages.
But intuitive for humans and optimal for agents are not the same thing. The hierarchy was designed to answer “who is responsible?” — an important human question that agents don’t need answered. The new design answers “what needs to happen next?” — which is the right question for a document-generation workflow.
What changes in v3:
- Agents become implementation details inside the Knowledge layer — the durable value is in evidence, governance, evaluation, and the document workflow
- Escalation fires on events (conflict, policy breach, missing data) — not on confidence scores
- The canonical model is the design constraint — the document isn’t an afterthought, it’s what everything is structured around
- Model-agnostic by default — local Gemma today, SOTA API tomorrow, same knowledge
What stays the same: LangGraph, LanceDB, BAAI/bge-small, FastAPI, SQLite, the YAML manifests, and the 13 domain specialists — which become callable skills within the Design stage rather than autonomous routing agents. Same knowledge, different invocation mechanism.
This is an extension of what we run, not a rebuild.
Questions about the design or the approach? Reach out on LinkedIn.

About the Author
Ajay Walia
AI {IT Architect} focusing on local-first multi-agent AI engineering, zero-data-egress systems. Ideator, Creator and Executor on Curious Bit.
Keep Reading

Aether, Grown Wild — The Implementation Journey (v2.6 → v2.8.2)
The second chapter of Aether: how a local-first team of IT architecture agents grew from a clean idea into a 13-agent, web-first, self-escalating system — and every bug that shaped it along the way.

RAG Chatbot from indexed public documentation
A domain-specific Retrieval-Augmented Generation assistant built with LangChain, OpenAI embeddings and FAISS that answers questions about the GitHub REST API strictly from indexed public documentation. Week 15 graded mini-project of the IITM Pravartak Professional Certificate Programme in Agentic AI and Applications.

I Built a Team of IT Architects using LLM That Live on MacBook — Meet Aether
How I built Aether — a local-first, multi-agent AI system that runs 10 specialist IT architecture advisors on a single MacBook M5 Pro, with no cloud, no API costs, and zero data egress.