A Field Guide to AI Chips
A beginner-to-intermediate field guide to the silicon powering modern AI. GPUs, TPUs, NPUs, CPUs, ASICs, FPGAs, edge chips and emerging architectures — what each is for, where you'll meet it, and how much it costs.
On this page
A Field Guide to AI Chips
Modern AI runs on a small zoo of specialised chips. Each evolved to handle a different workload — training a frontier model, answering a billion queries a day, recognising a face on your phone, keeping a drone alive in the air. This guide catalogues eight of them, with a stat block and a “where you’ll meet it” entry for each. Each section links to a deeper entry for the curious.
The Roll Call
| Chip | Best for | Memory & Interconnect | Cost & Access | Notable Specimens (2026) |
|---|---|---|---|---|
| GPU | Training + inference | 80–192GB HBM3/3e; NVLink 5, PCIe 5 | $25–40K each; cloud-only at scale | NVIDIA H100, B200, GB200 NVL72; AMD MI325X |
| TPU | Hyperscale training | 95–192GB HBM; OCS interconnect | Google Cloud only | TPU v5p, v6 Trillium |
| NPU | On-device AI | Shared LPDDR / unified memory | Bundled in device | Apple Neural Engine (M4), Intel AI Boost (Lunar Lake), Qualcomm Hexagon (8 Elite) |
| CPU | Orchestration & control plane | DDR5; PCIe 5, CXL | $1–15K; retail | Intel Xeon 6, AMD EPYC 9005 |
| ASIC | Inference at scale; specialised training | Custom HBM / SRAM; proprietary fabric | Cloud-only | AWS Inferentia2, Trainium2; Cerebras WSE-3; Groq LPU; SambaNova SN40L |
| FPGA | Custom, low-latency, adaptive | DDR/HBM; reprogrammable fabric | $5–50K each; cloud | AMD Versal AI Edge, Intel Agilex 7 |
| Edge AI | Mobile, robotics, IoT | LPDDR; low-power | $50–2000, embedded in product | NVIDIA Jetson Orin, Google Coral, Hailo-8 |
| Emerging | Frontier R&D | Wafer-scale SRAM / photonic / analog | Mostly research, limited cloud | Cerebras (covered above), Lightmatter, Mythic |
1 · GPU — Graphics Processing Unit
- Class
- Parallel beast
- Memory
- 80–192GB HBM3 / HBM3e
- Interconnect
- NVLink 5, PCIe 5, InfiniBand
- Power
- 350–1200W per die
- Habitat
- Hyperscale datacenters
- Cost
- $25–40K per card · cloud rental at scale
- Best Prey
- LLM training, diffusion, multimodal pretraining
- Specimens
- NVIDIA H100, B200, GB200 NVL72; AMD MI325X
GPUs are the apex predator of the AI hardware ecosystem in 2026. Originally designed for graphics, they turned out to be ideal for the dense matrix multiplications that dominate neural network training. NVIDIA’s H100 made the LLM era possible; B200 and the rack-scale GB200 NVL72 (72 GPUs treated as one machine, lashed together by NVLink switches) define the current frontier.
The reason GPUs dominate isn’t just parallel processing — it’s the combination of HBM (high-bandwidth memory mounted directly on the chip package), tensor cores (specialised matrix-multiply units), and a mature software ecosystem (CUDA, PyTorch, JAX) that nothing else has matched at scale. AMD’s MI325X is the only serious open-market competitor, and even it ships running CUDA-compatible code through ROCm translation.
The catch: you cannot really buy them. H100s and B200s ship into hyperscaler datacenters first and reach the open market — when they do — through Lambda, CoreWeave, AWS, and friends, rented by the hour at $2–8 each.
→ Full entry: Field Guide · GPUs
2 · TPU — Tensor Processing Unit
- Class
- Bespoke matrix engine
- Memory
- 95–192GB HBM (varies by generation)
- Interconnect
- OCS (Optical Circuit Switching) + ICI
- Power
- ~200–300W per chip
- Habitat
- Google Cloud (only)
- Cost
- Cloud rental only
- Best Prey
- Hyperscale training of Gemini-class models
- Specimens
- TPU v5p (training), v5e (inference), v6 Trillium
Google designed TPUs in-house to avoid paying NVIDIA’s margins on a workload they knew exactly — TensorFlow matrix multiplications at hyperscale. Each generation has narrowed the gap with GPUs on flexibility while widening it on energy efficiency per FLOP.
The architectural bet is the systolic array: a grid of multiply-add units that pumps data through in lockstep, achieving near-peak utilisation on matmul-heavy workloads. The trade-off is that anything outside that sweet spot (irregular memory access, highly dynamic shapes) runs less efficiently than on a GPU. The OCS-based interconnect lets Google rewire a TPU pod’s topology per job, which matters enormously at the scale of a Gemini training run.
You cannot buy a TPU. They exist exclusively inside Google Cloud, rented by the hour. Gemini was trained on them; many third parties (Anthropic for a stretch, plus enterprise customers) rent slices for their own runs.
→ Full entry: Field Guide · TPUs
3 · NPU — Neural Processing Unit
- Class
- On-device specialist
- Memory
- Shared LPDDR / unified system memory
- Interconnect
- SoC fabric (on-die)
- Power
- 5–40W
- Habitat
- Laptops, phones, tablets
- Cost
- Bundled — no separate purchase
- Best Prey
- Voice, camera AI, on-device LLMs, Copilot features
- Specimens
- Apple Neural Engine (M4), Intel AI Boost (Lunar Lake / Arrow Lake), Qualcomm Hexagon (8 Elite, X Elite)
NPUs are the chip type most people interact with every day without knowing it. They live inside the SoC of your phone or laptop, optimised for running already-trained models locally with extreme power efficiency. Voice transcription, Face ID, Pixel’s call screening, the on-device chat in Copilot+ PCs — all NPU workloads.
The defining trait is integer-quantised math (INT8 / INT4) at very low wattage. Where a datacenter GPU might pull 700W to serve a model, an NPU runs a comparable inference on the same model — quantised down — at 5–15W, with the weights sitting in the device’s main memory because there is no discrete accelerator memory to fill.
Microsoft now requires 40+ TOPS of NPU performance for a laptop to qualify as a “Copilot+ PC” — a forcing function that pushed Qualcomm, Intel and AMD into a 12-month arms race. As of 2026, top mobile SoCs ship 50–60 TOPS of NPU performance.
→ Full entry: Field Guide · NPUs
4 · CPU — Central Processing Unit
- Class
- General-purpose
- Memory
- DDR5 (system RAM)
- Interconnect
- PCIe 5, CXL
- Power
- 100–500W
- Habitat
- Every server, every workstation
- Cost
- $1–15K, retail and widely available
- Best Prey
- Orchestration, preprocessing, control plane, small-batch inference
- Specimens
- Intel Xeon 6, AMD EPYC 9005
CPUs aren’t obsolete — they’re indispensable. Every AI training run needs CPUs to feed data to the accelerators (decompression, tokenisation, augmentation), schedule jobs and run the control plane. The ratio matters: a typical training cluster pairs eight GPUs with one or two CPU sockets.
Modern server CPUs ship with AI-targeted extensions — AVX-512, AMX (Advanced Matrix Extensions), bf16 support — that let them handle small-batch inference and embedding generation reasonably well. For workloads under 7B parameters at low traffic, a CPU is often more economical than a dedicated accelerator.
What CPUs cannot do is train frontier models. The arithmetic density and memory bandwidth needed for LLM pretraining is 10–100× what a CPU delivers per watt. CPUs do the surrounding work; accelerators do the math.
→ Full entry: Field Guide · CPUs
5 · ASIC — Application-Specific Integrated Circuit
- Class
- Fixed-function accelerator
- Memory
- Custom HBM / on-die SRAM
- Interconnect
- Proprietary fabric
- Power
- 75–450W per chip
- Habitat
- Hyperscaler clouds (AWS, Cerebras, Groq, SambaNova)
- Cost
- Cloud rental only
- Best Prey
- Inference at scale, specialised training
- Specimens
- AWS Inferentia2, Trainium2; Cerebras WSE-3; Groq LPU; SambaNova SN40L
ASICs are chips designed for one thing and one thing only — and they’re brutally good at that thing. AWS Inferentia2 runs production inference for Anthropic, Amazon search and Alexa at a cost-per-token that beats GPUs. Trainium2 is AWS’s training equivalent, taking aim at NVIDIA’s H100/B200 dominance. Groq’s LPU posts inference latencies — sub-1ms first-token for many models — that GPUs simply cannot match.
The architectural philosophy is “build silicon for the specific math you do most often, throw away the rest.” Cerebras takes this furthest: their Wafer-Scale Engine 3 is a single chip the size of an entire silicon wafer (900,000 cores, 44GB on-die SRAM) that eliminates the multi-GPU communication overhead which plagues distributed training.
The price of specialisation: you cannot pivot. When the dominant architecture changes — and it does (Mamba, MoE, diffusion, JEPA) — ASICs designed for the last era stop being competitive overnight. GPUs hedge their bets; ASICs commit.
→ Full entry: Field Guide · ASICs
6 · FPGA — Field-Programmable Gate Array
- Class
- Reprogrammable logic
- Memory
- DDR / HBM (model-dependent)
- Interconnect
- PCIe; custom
- Power
- 50–300W
- Habitat
- Trading desks, 5G basebands, telecom, occasional inference
- Cost
- $5–50K each; cloud
- Best Prey
- Ultra-low-latency inference, custom protocols, evolving workloads
- Specimens
- AMD/Xilinx Versal AI Edge, Intel Agilex 7
FPGAs occupy a strange ecological niche. Unlike ASICs, their internal wiring is reprogrammable — you can compile a new circuit into them, deploy it, and reprogram it tomorrow. This makes them ideal for workloads that change faster than chip fabrication cycles (years), or where you need an ultra-low-latency that even ASICs struggle to deliver.
In AI specifically, FPGAs are rarely the first choice for mainstream training or inference — they are slower to develop for and harder to program than GPUs. Where they shine: when the model is small enough to fit, the latency budget is brutal (single-digit microseconds), and the workload spec might shift quarterly. Microsoft used FPGAs heavily in early Bing Search ranking and Azure networking; financial firms still run them for inline ML in trading.
For most readers, FPGAs will be a “did you know?” category rather than a chip you’ll ever deploy.
→ Full entry: Field Guide · FPGAs
7 · Edge AI — Mobile, Robotics, IoT
- Class
- Embedded inference
- Memory
- LPDDR, sometimes onboard SRAM
- Interconnect
- PCIe, MIPI, USB
- Power
- 1–25W
- Habitat
- Drones, robots, cameras, autonomous systems, sensors
- Cost
- $50–2000; embedded in product
- Best Prey
- Real-time inference, computer vision, robotics
- Specimens
- NVIDIA Jetson Orin, Google Coral / Edge TPU, Hailo-8, Ambarella CV5
Edge AI chips are NPUs’ cousins — same family, different role. Where an NPU lives inside a consumer laptop alongside other compute, an edge AI chip is purpose-built for an embedded device: a security camera, a drone, a forklift, a Tesla.
The defining constraints are size, power and latency. A camera processing 4K video at 30fps cannot afford to ship frames to a cloud GPU; it has to detect motion locally, identify objects locally and signal events within tens of milliseconds — on a few watts, because the device runs on battery or is fanless.
NVIDIA’s Jetson family is the broadest platform — same CUDA software stack as their datacenter GPUs, scaled down to 7–60W. Google’s Edge TPU is the smallest, cheapest and lowest power (Coral USB stick: $40, 2W). Hailo-8 and Ambarella sit in between, targeting industrial and automotive customers.
→ Full entry: Field Guide · Edge AI
8 · Emerging Architectures
- Class
- Experimental
- Memory
- Wafer-scale SRAM / photonic / analog
- Interconnect
- On-wafer / optical / in-memory
- Power
- Varies wildly
- Habitat
- Research labs, narrow cloud offerings
- Cost
- Mostly inaccessible; limited cloud
- Best Prey
- The next 10× efficiency leap
- Specimens
- Cerebras WSE-3 (wafer-scale); Lightmatter, Lightelligence (photonic); Mythic, IBM (analog/in-memory)
Three architectures sit at the frontier — promising, but not yet mainstream.
- Wafer-scale (Cerebras): one single chip the size of an entire silicon wafer. Eliminates multi-chip communication entirely; presents the whole system to software as a single device. Already commercial.
- Photonic / optical AI (Lightmatter, Lightelligence): perform matrix math using light interference instead of electricity. Potentially orders of magnitude lower energy per operation; currently limited to inference and constrained models.
- Analog / in-memory compute (Mythic, IBM, several startups): compute inside memory arrays using analog voltage levels. Removes the von-Neumann bottleneck — the constant shuttling of data between memory and compute — entirely. Promising for low-power inference; precision limitations make training hard today.
→ Full entry: Field Guide · Emerging Architectures
Current Industry Reality (2026)
- GPUs dominate training. Every frontier model — GPT-5, Claude, Gemini, Llama, Grok — is still trained on NVIDIA or AMD silicon at hyperscale.
- ASICs are ascendant in inference. AWS reports more than 40% of internal inference now runs on Inferentia and Trainium; Groq leads on latency-critical applications.
- NPUs are exploding on consumer devices. Every premium laptop and phone shipped in 2026 has a 40+ TOPS NPU.
- CPUs remain foundational. No accelerator runs without one.
- TPUs are Google-only. Gemini, Veo and Imagen were all trained on TPU v5p / v6.
Simplified View
| Use case | Typical chip |
|---|---|
| Train a GPT-class model | GPU clusters (or TPU pods if you're Google) |
| Run ChatGPT-class inference at scale | GPUs + ASICs (Inferentia, Groq, Trainium) |
| AI on laptop | NPU + integrated GPU |
| AI on phone | Mobile NPU |
| Robot or drone AI | Edge AI chips (Jetson, Hailo) |
| Ultra-low-latency custom AI | FPGA or ASIC |
The Industry Trend
Power and inference cost are now the binding constraints. A frontier model serving billions of queries spends more on inference electricity in a year than its entire training run cost. The economics force specialisation: train once on GPUs, serve forever on cheaper inference silicon. Expect the gap between training hardware (still GPU-dominant) and inference hardware (rapidly ASIC- and NPU-fragmented) to widen.
Test what you read
Quick quiz

About the Author
Ajay Walia
AI {IT Architect} focusing on local-first multi-agent AI engineering, zero-data-egress systems. Ideator, Creator and Executor on Curious Bit.
Keep Reading
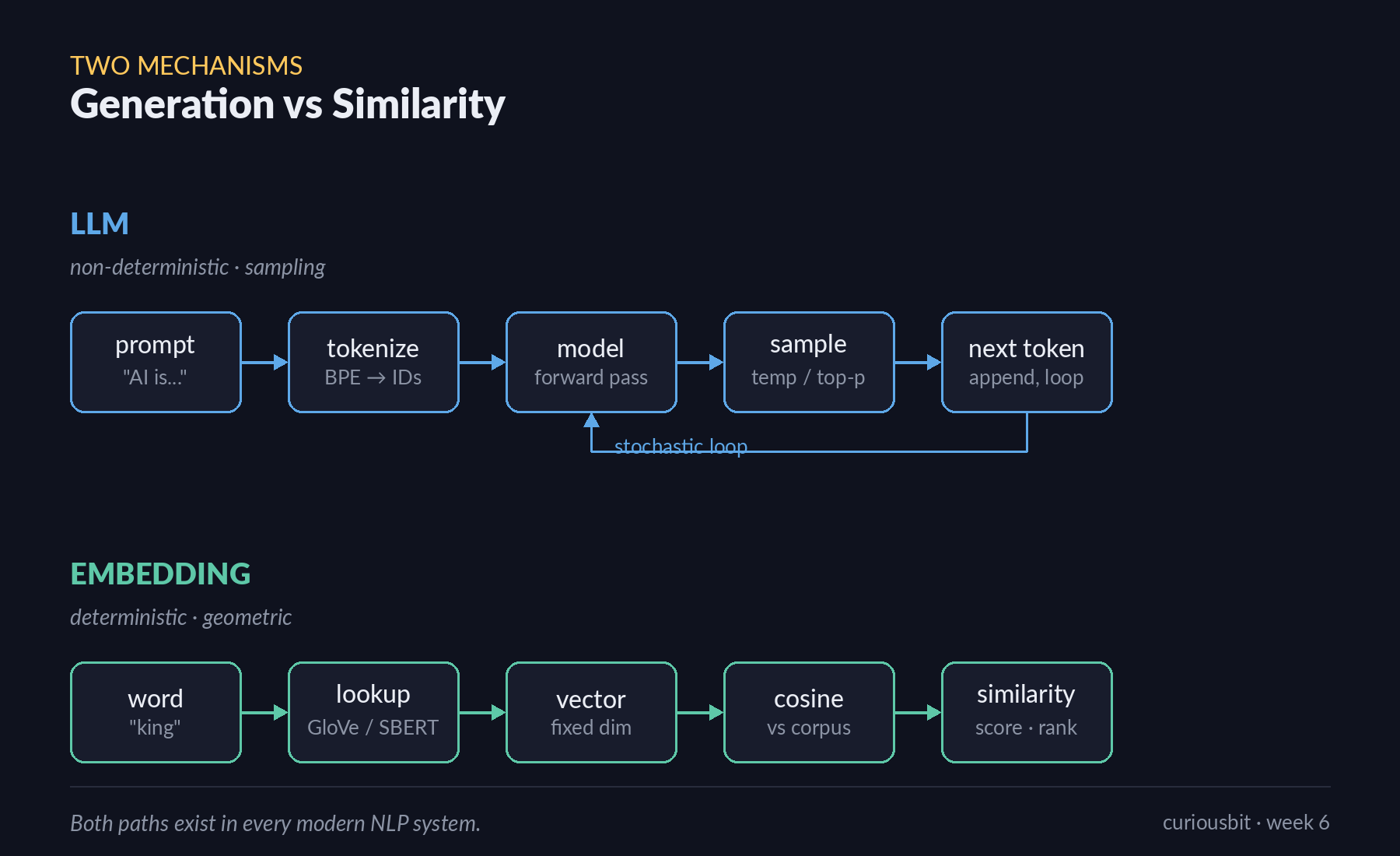
LLM & Embeddings — One Predicts Words. One Maps Meaning.
A walk through the two foundational mechanisms behind every modern NLP system — generative language models and similarity-based embeddings — using five hands-on exercises with Hugging Face and Gensim. Week 6 mini-project of the IITM Pravartak Professional Certificate Programme in Agentic AI.
About
Learner 🎓 · Negotiator 🤝 · Architect 🏗️ · Implementer 👷 · Surviving — enabled by AI. Currently exploring: AI, Hybrid Cloud, Automation, Networks, Digital Workplace<br><br><em>"He who thinks he knows, knows not.<br>He who knows that he does not know, knows."</em>